Do wyboru jedno dowolne zadanie.
Rozmiar około 30 stron, strona tytułowa, spis treści, cel i zakres, opis zagadnienia, schematy logiczne i fizyczne (min. 4), fotografie (dla sprzętu realnego), tabele adresacji, szczegółowy opis konfiguracji z uzasadnieniem, rozdział o problemach i rozwiązaniach, spisy tabel/ilustracji, bibliografia (min. 5 źródeł). Jeśli wstawiasz jakieś dane, realne foto to pamiętaj o RODO - usuń co nie jest potrzebne.
Spis treści zadań
- Projekt redundantnej infrastruktury okablowania i przełączania L2
- Routing Między-VLAN z redundancją bramy domyślnej FHRP
- Skalowalna topologia routingu dynamicznego Multi-Area OSPF
- Bezpieczny brzeg sieci korporacyjnej i strefa usług DMZ
- Migracja i wdrożenie stosu Dual-Stack IPv4/IPv6
- Projekt systemów wysokiej dostępności i Load Balancing serwerów
- Zaawansowane mechanizmy utwardzania bezpieczeństwa warstwy 2
- Bezpieczny dostęp zdalny z wykorzystaniem tuneli VPN IPsec/SSL
- Monitorowanie i analiza wydajności z SNMP, Syslog i NetFlow
- Zintegrowany projekt nowoczesnej sieci Centrum Danych (Capstone)
Część 1 & 2 Media transmisyjne, standardy Ethernet, Część 3 Przełączniki L2, STP, VLAN, EtherChannel.
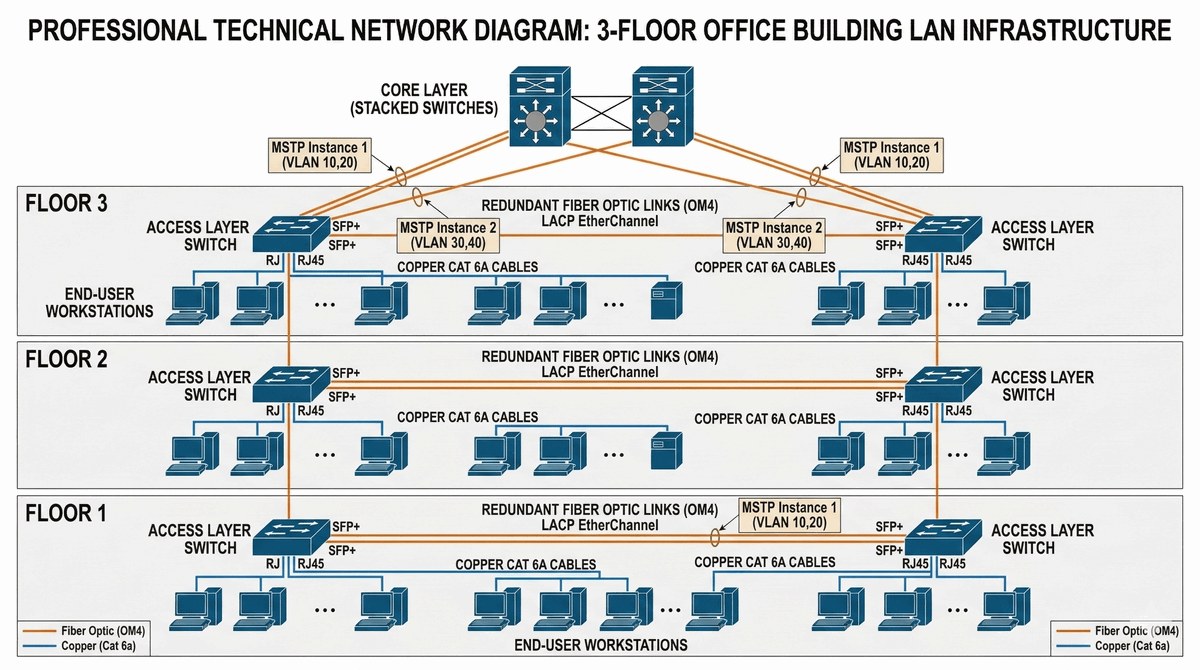
Celem projektu jest zaprojektowanie i wdrożenie redundantnej infrastruktury okablowania strukturalnego oraz przełączania warstwy 2 (L2) zgodnej ze standardami TIA-568 oraz IEEE. Projekt obejmuje fizyczne okablowanie pionowe (vertical cabling) między pomieszczeniami MDF a IDF oraz okablowanie poziome (horizontal cabling) do punktów abonenckich, z wykorzystaniem kabli miedziowych kategorii 6a (Cat6a) lub wyższej oraz kabli światłowodowych wielomodowych OM3/OM4 dla łączy między przełącznikami. Kluczowym elementem jest implementacja protokołu MSTP (Multiple Spanning Tree Protocol) z redundantnymi przełącznikami zapewniającymi ciągłość działania w przypadku awarii jednego urządzenia lub łącza. Projekt wymaga konfiguracji EtherChannel (LACP) dla agregacji łączy między przełącznikami, VLAN dla segmentacji ruchu, oraz PortFast i BPDU Guard na portach dostępowych dla szybszej konwergencji.
Firma przeprowadziła gruntowny remont biurowca trzypiętrowego i wymaga modernizacji infrastruktury sieciowej dostosowanej do obsługi 150 stanowisk komputerowych z dostępem do Internetu oraz zasobów sieciowych (serwer plików, drukarki). Obecna instalacja jest przestarzała (Cat5), nie zapewnia redundancji, a przełącznik centralny w piwnicy stanowi pojedynczy punkt awarii (single point of failure). Konieczne jest zaprojektowanie nowej struktury z przełącznikami w każdym pionie (IDF na każdym piętrze) połączonymi redundantnymi łączami do przełącznika głównego (MDF) z wykorzystaniem MSTP dla zapewnienia rezerwowej ścieżki STP (Blocking port w stanie Backup). Okablowanie musi być certyfikowane według standardu TIA-568 dla kategorii 6a z pomiarem tłumienia odbiciowego (return loss) i przesłuchu (crosstalk) miernikiem kategorii 6a (np. Fluke DSX-5000).
- 1. Inwentaryzacja istniejącej infrastruktury i plan nowego rozkładu punktów abonenckich.
- 2. Projekt okablowania pionowego: kable ślepo zakończone do IDF na każdym piętrze.
- 3. Projekt okablowania poziomego: gniazda RJ45 kat. 6a przy stanowiskach pracy.
- 4. Wybór przełączników L2 z portami 1GbE (dostęp) i 10GbE (uplink).
- 5. Konfiguracja VLAN dla funkcjonalnych stref (zarządzanie, dane, goście).
- 6. Konfiguracja MSTP z nazwą regionu i instancjami dla grup VLAN.
- 7. Konfiguracja EtherChannel (LACP) na łączach między przełącznikami.
- 8. Konfiguracja PortFast i BPDU Guard na portach dostępowych.
- 9. Testowanie redundancji: symulacja awarii przełącznika/uplink.
- 10. Pomiary certyfikacyjne okablowania miernikiem kat. 6a.
- 11. Walidacja przepustowości: testy iperf między segmentami.
- 12. Dokumentacja techniczna i as-built drawings.
- Przed rozpoczęciem konfiguracji sporządź dokładny plan adresacji IP i mapę VLAN - wersja papierowa ułatwia diagnozę błędów podczas wdrożenia.
- Przy projektowaniu okablowania pamiętaj o limitach TIA-568: max 90m link stały + 10m patchcord dla Cu Cat6a, odpowiednie odległości dla światłowodów OM4.
- MSTP skonfiguruj przed podłączeniem kabli między przełącznikami - najpierw skonfiguruj instancje MST z revision i nazwą regionu, dopiero potem łącz fizycznie.
- EtherChannel twórz w trybie LACP active-active - unikaj trybu "on" który nie negocjuje i może powodować pętle przy błędnej konfiguracji.
- Na portach dostępowych (użytkownicy) zawsze włącz PortFast + BPDU Guard - minimalizuje to czas konwergencji i blokuje nieautoryzowane przełączniki.
- Weryfikuj status STP poleceniem "show spanning-tree" - sprawdź który port jest Root Bridge i Blocking dla każdego VLAN.
- Testuj redundancję: odłącz jeden przełącznik i weryfikuj czy ruch przechodzi drugim - oddzielne testy dla obu kierunków.
- Urządzenia dostępowe łącz jako access switchport mode access - domyślny trunk może powodować problemy z hostami nieobsługującymi 802.1Q.
- Pamiętaj o VLAN pruning na trunkach - domyślnie wszystkie VLANy lecą wszędzie, ogranicz do minimum potrzebnych na danym łączu.
- Dokumentuj każdą zmianę konfiguracji w dzienniku - przy problemach łatwiej wrócić do znanego stanu niż debugować od zera.
Projekt powinien zawierać szczegółowy wykaz materiałów (BOM - Bill of Materials) obejmujący kable kategorii 6a, kable światłowodowe OM4, patchpanele, gniazda RJ45, listwy kablowe oraz złącza wraz z ich parametrami technicznymi i kosztorysem. Niezbędne jest przygotowanie schematu okablowania pionowego (vertical cabling) między MDF a IDF oraz schematu okablowania poziomego (horizontal cabling) z rozmieszczeniem punktów abonenckich na każdym piętrze zgodnie ze standardem TIA-568. Dokumentacja musi zawierać wyniki weryfikacji stanu drzewa rozpinającego MSTP dla poszczególnych instancji, wraz z analizą wybranych ścieżek dla każdego VLAN oraz dokumentację fotograficzną z pomiarów certyfikacyjnych wykonanych miernikiem kategorii 6a.
Część 3 VLANs, Część 4 Routing IPv4, Część 5 Urządzenia warstwy 3.
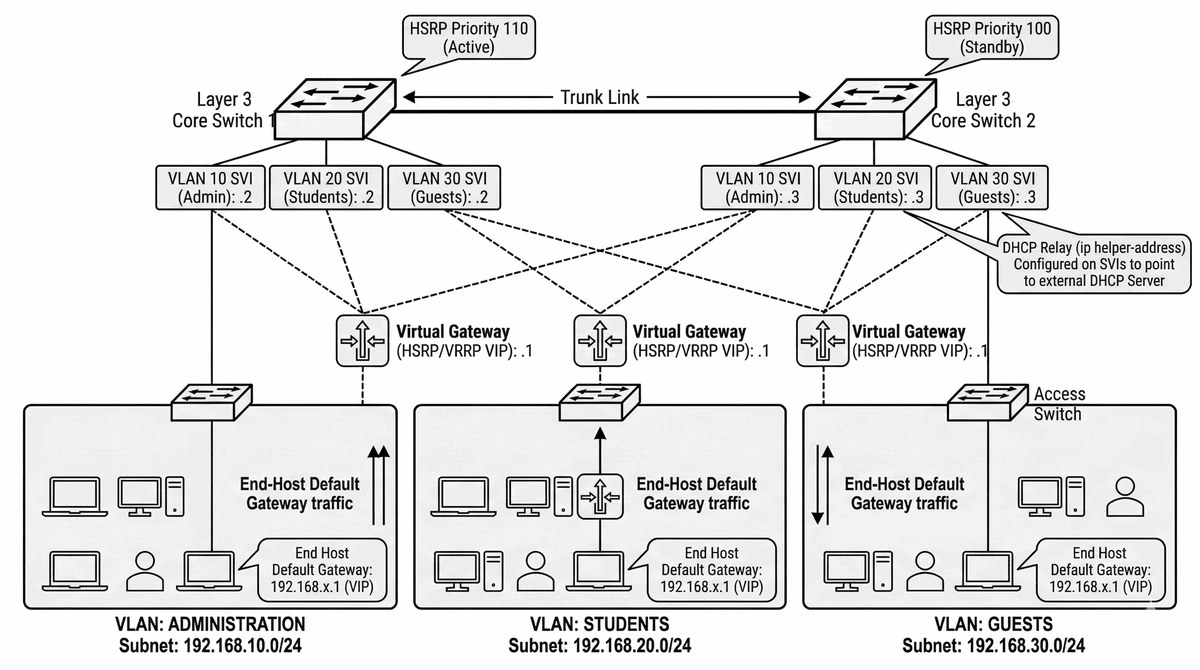
Celem projektu jest wdrożenie wydajnego routingu między izolowanymi segmentami sieci (VLAN) z zapewnieniem nieprzerwanej pracy bramy domyślnej w przypadku awarii jednego z urządzeń warstwy 3. Projekt obejmuje konfigurację dwóch przełączników rdzeniowych (L3) lub ruterów pracujących w klastrze protokołu FHRP (First Hop Redundancy Protocol) - HSRP (Hot Standby Router Protocol) w wersji 2 lub VRRP (Virtual Router Redundancy Protocol), które tworzą wirtualny adres IP (VIP) jako domyślną bramę dla stacji roboczych. Kluczowym elementem jest konfiguracja mechanizmu redundancji z uwzględnieniem priorytetów urządzeń (Active/Standby), funkcji preempt (auto-oddanie po odzyskaniu sprawności), trackowania interfejsów uplink (zmniejszenie priorytetu w przypadku awarii łącza) oraz autentykacji MD5 zabezpieczającej komunikaty protokołu przed atakami typu man-in-the-middle. Projekt wymaga również implementacji DHCP Relay (ip helper-address) dla obsługi serwera DHCP centralnego oraz testowania czasu failover, który standardowo wynosi około 3-5 sekund dla HSRP (hello 3s, hold 10s), ale może być zredukowany do milisekund przy użyciu timerów w trybie milisekundowym.
W budynku firmowym znajdują się trzy oddziały (Administracja, Studenci, Goście) rozmieszczone na osobnych piętrch, z których każdy pracuje w wydzielonej sieci VLAN (odpowiednio VLAN 10, 20, 30) z oddzielną pulą adresów IP. Komputery stacjonarne i urządzenia mobilne muszą mieć zapewnioną łączność między sobą poprzez routing realizowany przez przełączniki warstwy 3 (L3 Core Switches) z wykorzystaniem interfejsów SVI (Switch Virtual Interface). Awaria pojedynczego urządzenia routującego skutkowałaby utratą łączności dla setek użytkowników, dlatego konieczne jest wdrożenie mechanizmu redundancji bramy domyślnej FHRP - protokołu HSRPv2 (Hot Standby Router Protocol) lub VRRP (Virtual Router Redundancy Protocol), które tworzą wirtualny adres IP (VIP, np. .1 w każdej podsieci) jako wspólną bramę dla wszystkich hostów. Przełączniki L3 muszą być skonfigurowane jako Active/Standby z odpowiednimi priorytetami (np. 110/100), funkcją preempt umożliwiającą powrót do pierwotnego urządzenia po awarii, oraz mechanizmem trackowania łączy uplink, który automatycznie obniży priorytet w przypadku utraty łączności w kierunku Internetu lub sieci backbone. Adresacja IP dla stacji roboczych ma być realizowana przez centralny serwer DHCP, a przełączniki L3 pełnią rolę DHCP Relay (ip helper-address) przekazującego żądania do serwera. Czas przełączenia (failover) przy poprawnej konfiguracji timerów (HSRP hello 3s, hold 10s) wynosi około 3-5 sekund, co jest akceptowalne dla większości zastosowań biurowych, ale wymaga weryfikacji podczas testów obciążeniowych.
- 1. Zdefiniowanie bazy VLAN (ID 10, 20, 30) i przypisanie nazw funkcjonalnych.
- 2. Konfiguracja interfejsów SVI (Switch Virtual Interface) na obu przełącznikach Core L3.
- 3. Ustalenie fizycznej adresacji IP dla interfejsów VLAN (np. .2 i .3 w każdej podsieci).
- 4. Konfiguracja protokołu HSRP (Hot Standby Router Protocol) w wersji 2.
- 5. Ustalenie wirtualnego adresu IP (VIP) jako bramy domyślnej (np. .1).
- 6. Konfiguracja priorytetów HSRP (110 dla Active, 100 dla Standby) z funkcją preempt.
- 7. Implementacja mechanizmu Interface Tracking dla łączy uplink.
- 8. Konfiguracja autentykacji MD5 dla wiadomości HSRP/VRRP.
- 9. Konfiguracja puli DHCP na serwerze centralnym dla wszystkich VLAN-ów.
- 10. Włączenie funkcji DHCP Relay (ip helper-address) na interfejsach SVI.
- 11. Testowanie przełączania (failover) poprzez odłączenie aktywnego urządzenia L3.
- 12. Monitorowanie stanów FHRP poleceniem "show standby brief".
- 13. Optymalizacja timerów HSRP (msec hello/hold) dla szybszej konwergencji.
- 14. Zabezpieczenie dostępu administracyjnego do bramek (SSH, ACL).
- Przed konfiguracją HSRP zweryfikuj działanie routingu L3 - oba przełączniki muszą mieć skonfigurowane interfejsy SVI z adresami IP.
- VIP (Virtual IP) musi być w tej samej podsieci co adresy fizyczne, ale NIGDY nie może być przypisany do żadnego fizycznego interfejsu.
- Ustaw priorytet wyższy (np. 110) na urządzeniu które ma być Active - domyślny priorytet to 100, większość wygrywa.
- Włącz funkcję preempt - pozwala powrócić do pierwotnego Active po awarii i naprawie, bez tego Standby zostaje na zawsze.
- Skonfiguruj trackowanie interfejsu uplink - priorytet obniża się automatycznie gdy łącze w dół, nie gdy sam przełącznik pada.
- HSRP wymaga autentykacji MD5 - bez niej atakujący może przejąć rolę Active i przechwycić ruch (MITM).
- Testuj failover: wyłącz przełącznik Active i sprawdź czy ruch idzie przez Standby - weryfikuj ping z dowolnego VLAN.
- Sprawdź wartości timerów: domyślne hello=3s, hold=10s dają ~3-5s failover - nie ruszaj bezpiecznika poniżej 1s/4s.
- Na switchach warstwy 3 upewnij się że ip routing włączony - bez tego SVI nie ma routingu między VLAN.
- DHCP Relay (ip helper-address) MUSI być na obu przełącznikach Core - żądania idą przez fizyczne interfejsy, nie VIP.
Dokumentacja projektowa powinna zawierać tabelę adresów VIP (Virtual IP) dla każdego VLAN z przypisanymi fizycznymi adresami interfejsów Active i Standby oraz priorytetami HSRP. Niezbędne jest przeprowadzenie testów failover obejmujących symulację awarii poprzez wyłączenie przełącznika Active i pomiar czasu przełączenia (failover time) - standardowo 3-5 sekund dla domyślnych timerów HSRP. Dokumentacja powinna zawierać logi systemowe z serwera Syslog zarejestrowane podczas symulowanej awarii, pokazujące komunikaty o zmianie stanu z Active na Standby. Wymagana jest również analiza wpływu mechanizmu trackowania interfejsów uplink na czas przełączenia w scenariuszu, gdy awarii ulega łącze do Internetu, a nie sam przełącznik.
Część 4 Protokoły routingu (IGP), OSPF, hierarchia sieci.
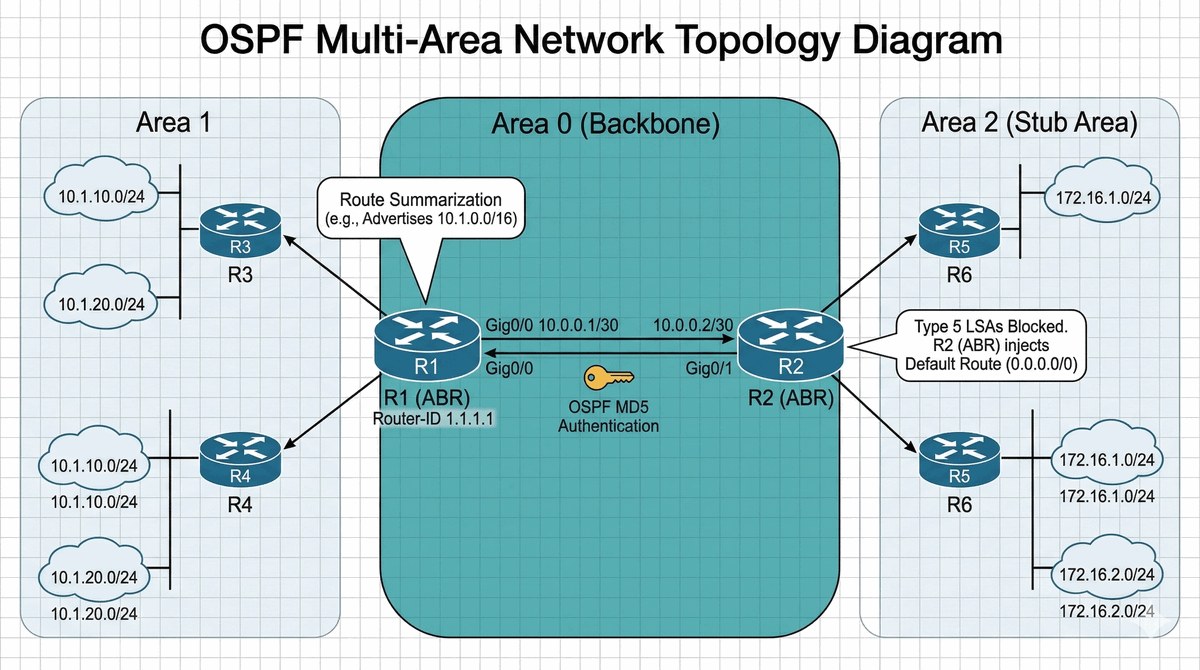
Celem projektu jest zaprojektowanie i weryfikacja wieloobszarowej domeny OSPF (Open Shortest Path First) w celu optymalizacji tablic routingu i ograniczenia propagacji zmian w dużych sieciach korporacyjnych. Projekt obejmuje konfigurację hierarchicznej struktury obszarów z wykorzystaniem Area 0 (Backbone) jako centralnego punktu łączącego obszary brzegowe (Area 1, 2, itd.) poprzez rutery ABR (Area Border Router). Kluczowym elementem jest zastosowanie sumaryzacji tras (area range) na ruterach ABR w celu redukcji rozmiaru bazy danych LSDB (Link State Database) i minimalizacji propagacji LSA Type 3 między obszarami. Projekt wymaga również rozważenia zastosowania obszarów typu Stub lub Totally Stubby dla oddziałów bezpośrednio podłączonych do ABR, co eliminuje LSA Type 5 (external routes) z tablic rutera oddziałowego, lub NSSA (Not-So-Stubby Area) gdy wymagana jest redystrybucja tras z innych protokołów. Wymagana jest autentykacja OSPF (MD5 lub HMAC-SHA) na wszystkich łączy międzyruterowych oraz monitorowanie LSDB i procesu SPF dla weryfikacji poprawnej konwergencji - czas zbiegania wynosi standardowo około 5-40 sekund w zależności od wielkości obszaru i timerów SPF.
Przedsiębiorstwo z siedzibą w mieście A (centrala) posiada dwa oddziały zlokalizowane w miastach B i C, połączone dedykowanymi łączami WAN o przepustowości 1 Gbps. W centrali pracują rutery rdzeniowe oraz serwery dostępne dla wszystkich lokalizacji, natomiast oddziały dysponują lokalnymi przełącznikami i stacjami roboczymi. W celu zapewnienia optymalnej wymiany informacji routingu i minimalizacji rozmiaru tablic routingu konieczne jest wdrożenie protokołu routingu dynamicznego OSPF w architekturze Multi-Area, w której centrala pełni rolę Area 0 (Backbone) będącą hubem łączącym wszystkie obszary, a każdy oddział stanowi osobny obszar (np. Area 1 dla miasta B, Area 2 dla miasta C). Ruter ABR (Area Border Router) w centrali musi sumaryzować trasy z poszczególnych obszarów za pomocą polecenia area range, co redukuje rozmiar bazy LSDB (Link State Database) w oddziałach i ogranicza propagację LSA Type 3 do minimum. Oddziały bez bezpośredniego dostępu do sieci zewnętrznych mogą zostać skonfigurowane jako obszary typu Stub (bez LSA Type 5) lub Totally Stubby (bez LSA Type 3, 4, 5 poza default route), co dodatkowo zmniejsza obciążenie CPU rutera oddziałowego. Autentykacja MD5 na wszystkich łączy międzyruterowych zabezpiecza protokół przed atakami typu route injection, natomiast interfejsy do których podłączone są stacje robocze (porty dostępowe) muszą być skonfigurowane jako passive-interface, aby nie nawiązywać relacji sąsiedztwa z hostami i nie generować niepotrzebnego ruchu OSPF. Konwergencja sieci (czas potrzebny na wyliczenie nowych ścieżek po zmianie topologii) dla typowych scenariuszy awaryjnych powinna wynosić poniżej 40 sekund, a wartość ta musi być zweryfikowana podczas testów failover.
- 1. Zaprojektowanie schematu adresacji IP z możliwością łatwej sumaryzacji (VLSM).
- 2. Konfiguracja Process ID OSPF oraz unikalnego Router ID na każdym urządzeniu.
- 3. Przypisanie interfejsów do odpowiednich obszarów (Area 0 - Backbone, Area 1, Area 2).
- 4. Konfiguracja interfejsów pasywnych (passive-interface) na portach użytkowników.
- 5. Implementacja sumaryzacji tras na ruterach ABR (Area Border Router).
- 6. Konfiguracja obszarów typu Stub lub Totally Stubby w celu redukcji tablicy LSA.
- 7. Włączenie autentykacji OSPF MD5 na wszystkich łączach międzyruterowych.
- 8. Zarządzanie kosztami łączy w celu wymuszenia optymalnych ścieżek (bandwidth/cost).
- 9. Redystrybucja trasy domyślnej z rutera brzegowego (default-information originate).
- 10. Monitoring sąsiedztwa OSPF poleceniem "show ip ospf neighbor".
- 11. Analiza bazy danych Link State Database (show ip ospf database).
- 12. Testowanie redundancji tras poprzez wyłączanie poszczególnych linków.
- 13. Optymalizacja konwergencji poprzez dostosowanie timerów SPF (LSA Throttling).
- 14. Konfiguracja tuneli wirtualnych (Loopback) na potrzeby stabilności RID.
- Router ID ustaw na interfejsie Loopback - jest zawsze aktywny (nie zależy od fizycznego portu), stabilniejszy od RID na interfejsie fizycznym.
- Każdy router musi mieć unikalny RID - w formacie IPv4 np. 1.1.1.1, 2.2.2.2 w danym procesie OSPF.
- Area 0 (Backbone) musi być ciągły - wszystkie obszary łączą się do Area 0 przez ABR, przerywa => nie ma routingu.
- Design obszarów: małe obszary (mniej routerów) = szybsza konwergencja - oddział w osobnym obszarze izoluje zmiany.
- Sumaryzacja NA GRANICY obszaru (ABR) - nie w środku obszaru. Polecenie "area X range" na ABR.
- Stub/Totally Stub dla oddziałów bez zewnętrznych tras - redukuje LSA5 i LSA3 w oddziale, tylko default route.
- NSSA gdy oddział ma własny protokół BGP/redystrybucję - potrzebuje LSA7 które ABR konwertuje na LSA5.
- Autentykacja MD5 na każdym łączu - OSPF bez autentykacji podatny na route injection (fałszywe LSA).
- Passive interface na portach do hostów - hosty nie są routerami, niepotrzebne sąsiedztwo na portach dostępowych.
Dokumentacja musi zawierać szczegółową analizę bazy danych Link State Database (LSDB) na każdym ruterze z wyświetleniem wszystkich typów LSA (LSA Type 1 - Router LSA, LSA Type 2 - Network LSA, LSA Type 3 - Summary LSA) i ich liczby w poszczególnych obszarach. Wymagane jest przedstawienie obliczeń adresacji sumarycznej (route summarization) z zastosowaniem VLSM, pokazujące w jaki sposób mniejsze podsieci zostały zagregowane do większych prefiksów na ruterach ABR w celu redukcji rozmiaru tablicy routingu. Projekt powinien zawierać schemat hierarchiczny domeny OSPF z zaznaczonymi obszarami, routerami ABR i ASBR oraz przepływem LSA między obszarami.
Część 4 NAT/PAT, Część 5 Firewalle, IPS/IDS, DPI.
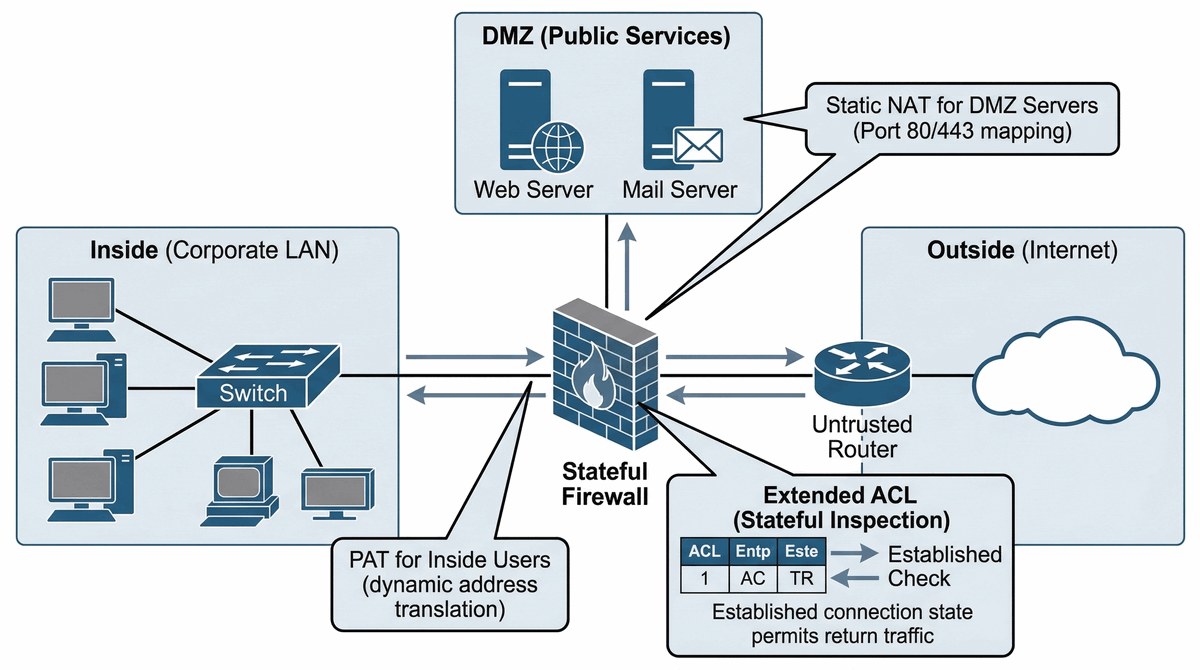
Celem projektu jest zabezpieczenie styku sieci lokalnej z Internetem oraz wystawienie usług publicznych (WWW, DNS, Mail) w odseparowanej strefie DMZ (Demilitarized Zone) zgodnie z zasadą defense-in-depth i modelem bezpieczeństwa strefowego. Projekt obejmuje wdrożenie dwuzaporowej architektury (dual-firewall) z trzema strefami bezpieczeństwa: Inside (sieć wewnętrzna, zaufana), Outside (Internet, niezaufana) i DMZ (strefa pośrednia dla usług publicznych). W strefie Inside stosowany jest NAT z przeciążeniem (PAT/overload) dla translacji adresów prywatnych na publiczne (Dynamic PAT), natomiast dla usług w DMZ wymagany jest NAT statyczny (Static NAT lub Destination NAT) mapujący publiczne adresy IP na wewnętrzne serwery. Kluczowym elementem jest implementacja stanowej inspekcji pakietów (Stateful Packet Inspection) oraz rozszerzonych list ACL (Extended ACL) z zasadą domyślnego blokowania (Deny All Incoming) na interfejsie Outside. Projekt wymaga również zabezpieczenia przed atakami DoS (limity połączeń, tcp-intercept), implementacji inspekcji protokołów aplikacyjnych (ALG) dla FTP, SIP, H.323 oraz logowania zdarzeń do zewnętrznego serwera Syslog dla compliance i forensyki bezpieczeństwa.
Firma korporacyjna posiada sieć wewnętrzną (Inside) z około 500 stacjami roboczymi w prywatnej przestrzeni adresowej RFC 1918 (np. 192.168.0.0/16), która wymaga bezpiecznego dostępu do Internetu oraz publicznie dostępne usługi WWW, DNS i SMTP działające w strefie zdemilitaryzowanej (DMZ). Brzeg sieci zbudowany na routerze/firewallu musi realizować translację adresów NAT/PAT dla ruchu wychodzącego z sieci wewnętrznej (Dynamic PAT z puli publicznych IP), natomiast serwery w DMZ muszą być dostępne z Internetu przez statyczne mapowanie NAT (Static NAT, 1:1) lub Destination NAT na określone porty, zachowując przy tym pełną izolację między strefami zgodnie z modelem bezpieczeństwa strefowego. Wszystkie interfejsy muszą być przypisane do odpowiednich stref bezpieczeństwa (Inside, Outside, DMZ), a polityka domyślna na interfejsie zewnętrznym (Outside) to DENY ALL dla ruchu przychodzącego, z wyjątkami jawnie zdefiniowanymi w Extended ACL tylko dla dozwolonego ruchu (np. HTTP/HTTPS do serwera WWW w DMZ). Stateful Packet Inspection (SPI) zapewnia, że odpowiedzi na wychodzące połączenia są automatycznie allowowane, a pakiety przychodzące niezwiązane z istniejącymi sesjami są blokowane. Konieczna jest ochrona przed atakami DoS/DDoS (limity rate-limit, tcp-intercept dla half-open connections) oraz zabezpieczenie urządzenia brzegowego przed spoofingiem adresów (Unicast Reverse Path Forwarding - uRPF). Logowanie wszystkich zdarzeń bezpieczeństwa (Denied packets, NAT translations) do zewnętrznego serwera Syslog umożliwia późniejszą analizę forensyki i audyt compliance. Testowanie musi obejmować weryfikację, że użytkownik z Internetu NIE może nawiązać połączenia TCP do hosta w sieci Inside, ale serwer WWW w DMZ jest osiągalny na porcie 80/443.
- 1. Inicjalizacja trzech stref bezpieczeństwa (Inside, Outside, DMZ) na firewallu/routerze.
- 2. Konfiguracja NAT dynamicznego z przeciążeniem (PAT) dla strefy Inside.
- 3. Przypisanie publicznej puli adresów IP dla wychodzącego ruchu korporacyjnego.
- 4. Konfiguracja Static NAT (Destination NAT) dla serwerów w DMZ (port 80, 443).
- 5. Implementacja list kontroli dostępu (Standard ACL i Extended ACL).
- 6. Konstrukcja polityki "Deny All" na interfejsie Outside jako punktu wyjścia.
- 7. Włączenie inspekcji ruchu (Stateful Inspection) dla pakietów TCP, UDP i ICMP.
- 8. Konfiguracja reguł dostępu chroniących DMZ (zezwolenie tylko na wymagane porty).
- 9. Implementacja limitowania połączeń (Connection Limits) w celu ochrony przed DoS.
- 10. Zabezpieczenie urządzenia przed atakami typu Spoofing (uRPF).
- 11. Konfiguracja logowania zdarzeń bezpieczeństwa do zewnętrznego serwera Syslog.
- 12. Testowanie dostępności usług z Internetu oraz izolacji między strefami.
- 13. Weryfikacja translacji NAT poleceniem "show ip nat translations".
- 14. Przegląd statystyk trafień ACL (Access-list counters).
- Zacznij od polityki DENY ALL - domyślna polityka na Outside musi być deny, potem dodawaj tylko potrzebne wyjątki.
- Inside to domyślnie trust, Outside i DMZ to domyślnie untrust - nie myl kolejności przy konstruowaniu ACL.
- NAT działa przed ACL wyjściem - testuj translację poleceniem "show ip nat translations" w czasie rzeczywistym.
- PAT (overload) dla Inside - jedno IP zewnętrzne dla setek hostów wewnętrznych - sprawdź czy starczy portów (65535).
- Static NAT dla serwera WWW w DMZ - mapowanie 1:1 np. zewnątrz:80 na wewnątrz:80 - przed pingiem odblokuj ICMP.
- Stateful inspection włączony - odpowiedzi na połączenia outgoing automatycznie puszczane, nie wymagają reguły.
- uRPF Strict - sprawdź czy źródło pakietu pasuje do trasy, blokuje spoofing - uważ na asymetryczny routing.
- DoS protection: rate-limit na interfejsie Outside - ogranicz pakiety/sekundę, tcp-intercept na partial connections.
- Logowanie włącz na "deny ip any any log" - bez logów nie wiesz kogo blokujesz, audyt forensyczny.
Projekt wymaga przygotowania macierzy ruchu (Access Matrix) dokumentującej dozwolone połączenia między strefami Inside, Outside i DMZ z wyszczególnieniem protokołów, portów i kierunków inicjacji. Niezbędne jest przedstawienie statystyk dopasowań ACL (access-list counters) pokazujące liczbę dopasowanych i odrzuconych pakietów dla każdej reguły w okresie testowym. Dokumentacja powinna zawierać szczegółowy wykres przepływu pakietu przez urządzenie brzegowe dla typowego scenariusza (np. żądanie HTTP z Inside do Internetu oraz żądanie WWW z Internetu do serwera w DMZ), z zaznaczeniem miejsc translacji NAT i filtrowania ACL.
Część 4 Adresowanie IPv4 vs IPv6, Część 5 Routing nowej generacji.
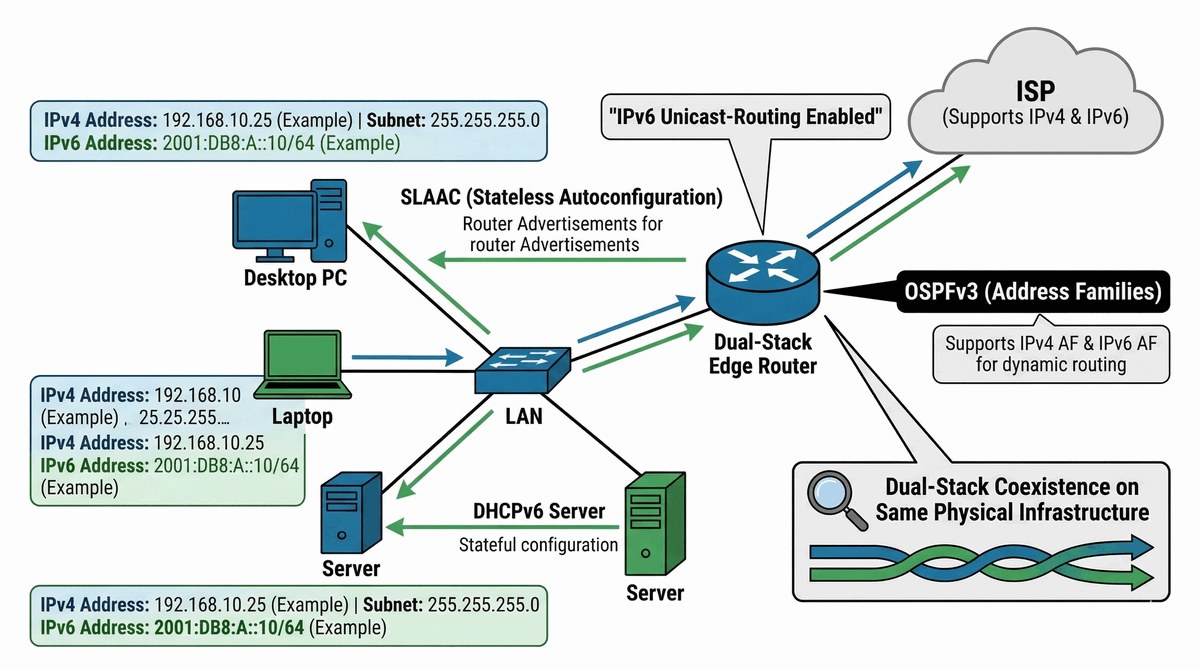
Celem projektu jest przygotowanie infrastruktury sieciowej do obsługi protokołu IPv6 bez przerywania świadczenia usług w standardzie IPv4, realizując model Dual-Stack (obsługa obu stosów protokołów jednocześnie). Projekt obejmuje zaplanowanie schematu adresacji IPv6 z wykorzystaniem prefiksu GUA (Global Unicast Address) otrzymanego od ISP (np. /48) oraz podział na podsieci /64 dla segmentów LAN (zgodnie z RFC 5375 - minimalna wielkość podsieci IPv6 to /64 dla obsługi SLAAC i ND). Kluczowym elementem jest wdrożenie mechanizmów autokonfiguracji: bezstanowej (SLAAC - Stateless Address Autoconfiguration) dla auto-przydzielania adresów z prefixu + EUI-64 lub losowych (RFC 4941), lub stanowej usługi DHCPv6 dla pełnej kontroli adresacji i dodatkowych opcji (DNS, NTP). Routing IPv6 realizowany jest przez OSPFv3 (Open Shortest Path First version 3) z wykorzystaniem 32-bitowych Router ID w formacie IPv4, działającym niezależnie od routingu IPv4. Projekt wymaga również implementacji zabezpieczeń specyficznych dla IPv6: RA Guard przed atakami Router Advertisement Spoofing, ND (Neighbor Discovery) Inspection, DHCPv6 Guard oraz IPv6 ACL dla ochrony interfejsów VTY i interfejsów zarządzania.
Operator ISP dostarczył firmie prefix IPv6 /48 (np. 2001:DB8:ACAD::/48) w ramach globalnej puli adresów GUA (Global Unicast Address), a jednocześnie firma nadal eksploatuje setki usług i hostów opartych na IPv4, których adresy prywatne (RFC 1918) muszą zostać zachowane. Konieczne jest wdrożenie modelu Dual-Stack, w którym każdy router i przełącznik L3 obsługuje jednocześnie stos IPv4 i IPv6, a stacje robocze użytkowników mogą komunikować się w obu protokołach. Schemat adresacji IPv6 musi być zaplanowany hierarchicznie: prefix /48 dzielony na subprefixy /56 lub /60 dla poszczególnych lokalizacji/oddziałów, a każdy segment LAN otrzymuje prefix /64 zgodnie z RFC 5375, co jest minimalną wielkością sieci wymaganą do poprawnego działania SLAAC (Stateless Address Autoconfiguration) i Neighbor Discovery (ND). Hosty w segmencie LAN mogą uzyskiwać adres IPv6 automatycznie przez SLAAC (rutator rozgłasza prefix przez Router Advertisement - RA), opcjonalnie rozszerzone o informacje z DHCPv6 (stateless DHCPv6 dla DNS, NTP), lub w pełni przez Stateful DHCPv6 gdy wymagana jest centralna kontrola puli adresów. Routing IPv6 realizowany jest przez OSPFv3 (OSPF version 3), który działa niezależnie od OSPFv2 dla IPv4, wykorzystując 32-bitowy Router ID w formacie adresu IPv4 (np. 1.1.1.1). Zabezpieczenia specyficzne dla IPv6 obejmują: RA Guard chroniący przed fałszywymi routerami IPv6 (atak Rogue Router Advertisement), DHCPv6 Guard blokujący nieautoryzowane odpowiedzi DHCPv6, ND Inspection walidujący pakiety Neighbor Discovery względem tabeli DHCPv6 binding, oraz IPv6 ACL zabezpieczające interfejsy VTY i zarządzania przed nieautoryzowanym dostępem. Testowanie musi potwierdzić łączność end-to-end (ping, traceroute) zarówno w IPv4 jak i IPv6 między hostami w różnych podsieciach, a dokumentacja powinna zawierać pełen schemat adresacji IPv6 w notacji skróconej (niewypełnionej zerami).
- 1. Inwentaryzacja zasobów i sprawdzenie wsparcia dla IPv6 na wszystkich urządzeniach.
- 2. Zaprojektowanie struktury podsieci IPv6 bazującej na prefiksie otrzymanym od ISP (np. /48).
- 3. Włączenie routingu IPv6 poleceniem "ipv6 unicast-routing".
- 4. Konfiguracja adresacji Global Unicast (GUA) na interfejsach ruterów.
- 5. Implementacja bezstanowej autokonfiguracji (SLAAC) na interfejsach LAN.
- 6. Konfiguracja DHCPv6 (Stateless dla DNS lub Stateful dla pełnej kontroli).
- 7. Inicjalizacja protokołu OSPFv3 w celu routowania obu stosów (Address Families).
- 8. Konfiguracja priorytetów ID dla OSPFv3 (wymagany format 32-bitowy IPv4).
- 9. Implementacja IPv6 ACL w celu zabezpieczenia wirtualnych terminali (VTY).
- 10. Zabezpieczenie przed atakami RA Spoofing za pomocą RA Guard.
- 11. Konfiguracja Neighbor Discovery (ND) Inspection na przełącznikach.
- 12. Testowanie łączności "End-to-End" dla obu protokołów (ping -6).
- 13. Weryfikacja tablicy sąsiedztwa IPv6 (show ipv6 neighbors).
- 14. Monitorowanie statystyk routingu OSPFv3 dla obu rodzin adresów.
- Włącz ipv6 unicast-routing przed konfiguracją - bez tego router ignoruje pakiety IPv6 i nie odpowiada na routing.
- Prefiks /48 od ISP dzielisz na /64 dla każdego segmentu LAN - to minimum dla SLAAC (RFC 4862), mniejszy nie działa.
- Adresy link-local auto-konfigurowane z EUI-64 - ale możesz też użyć losowych (RFC 4941) dla prywatności.
- Na routerze włącz router advertisement (RA) dla SLAAC - hosty same biorą prefix z RA i doklejają interfejs ID.
- DHCPv6 stateless dostarcza tylko DNS/NTP bez adresów - współpracuje z SLAAC. Stateful = pełna kontrola puli.
- OSPFv3 wymaga oddzielnego procesu dla IPv6 - Router ID w formacie IPv4 np. 1.1.1.1 obowiązkowy.
- IPv6 ACL weryfikuje źródłowy adres - bez tego pakiety z nieznanych źródeł mogą przechodzić.
- RA Guard na switchu warstwy 2 blokuje fałszywe routery - włącz na portach dostępowych, trusted uplink.
- Wireshark pokaże ICMPv6 (NS/NA/RS/RA) - weryfikuj że Neighbor Discovery działa przed testowaniem.
- Dual-stack: oba protokoły na tym samym interfejsie - weryfikuj routing show ip route i show ipv6 route.
Dokumentacja powinna zawierać kompletny plan adresacji IPv6 w notacji skróconej (z pominięciem niewypełnionych zer) z podziałem na prefix /48 otrzymany od ISP, subprefixy /56 lub /60 dla poszczególnych lokalizacji oraz prefixy /64 dla każdego segmentu LAN. Wymagana jest analiza przechwyconych pakietów ICMPv6 z wykorzystaniem Wireshark, pokazująca działanie mechanizmu Neighbor Discovery (NS - Neighbor Solicitation, NA - Neighbor Advertisement, RS - Router Solicitation, RA - Router Advertisement) oraz proces auto-konfiguracji adresu IPv6 metodą SLAAC z wykorzystaniem identyfikatora interfejsu w formacie EUI-64. Dokumentacja musi zawierać dowody potwierdzające działanie trybu Dual-Stack na stacjach roboczych, w tym zrzuty ekranu z wynikami poleceń ipconfig /all (Windows) lub ip -6 addr show (Linux) wykazujących jednoczesną konfigurację adresów IPv4 i IPv6.
Część 5 Load Balancery (L4/L7), Health Checks, proxy serwery.
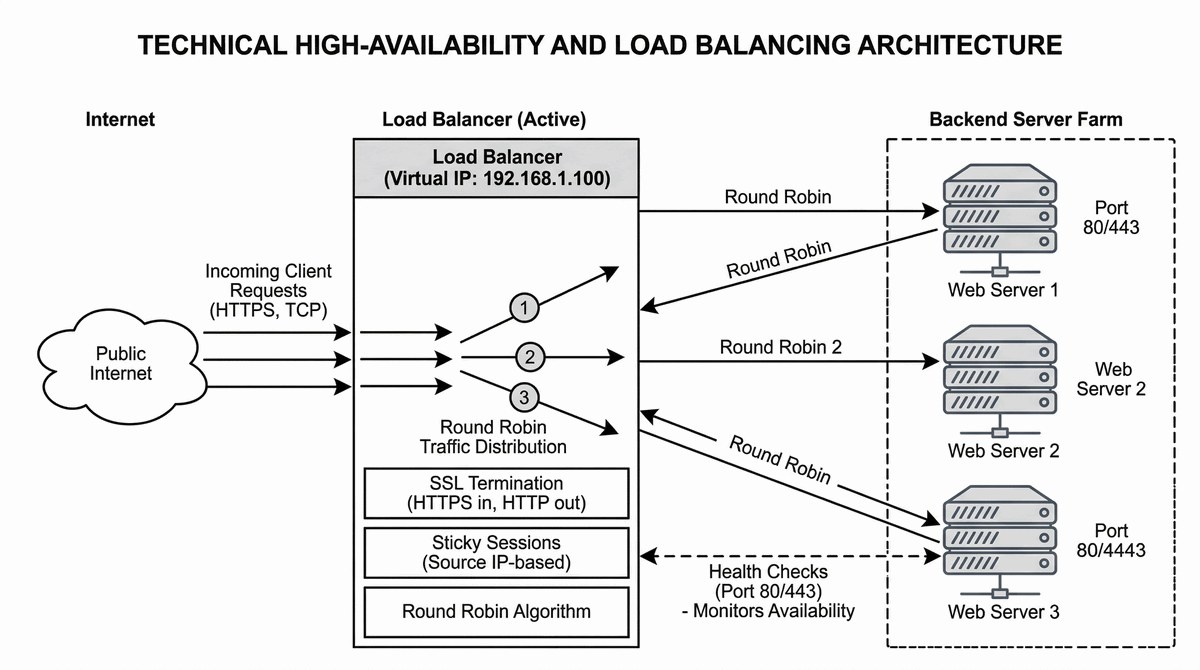
Celem projektu jest skalowanie usług sieciowych i zapewnienie ich wysokiej dostępności poprzez rozkładanie ruchu (load balancing) na wiele serwerów fizycznych lub wirtualnych w farmie backend. Projekt obejmuje konfigurację urządzenia lub oprogramowania Load Balancer (L4/L7) takiego jak F5 BIG-IP, HAProxy, Nginx, Citrix NetScaler lub funkcje LB w MikroTik/router. Kluczowym elementem jest implementacja algorytmów rozkładu ruchu: Round Robin (równy podział), Least Connections (najmniej połączeń), IP Hash (klient na ten sam serwer), Weighted Round Robin (z wagami) lub innych w zależności od charakterystyki ruchu. Wymagana jest konfiguracja Health Check (sprawdzanie zdrowia) dla każdego serwera backend - najczęściej przez periodyczne odpytywanie portu TCP (np. 80/443) lub wysyłanie żądań HTTP GET z weryfikacją kodu odpowiedzi, z parametrami Fall (ile niepowodzeń przed wyłączeniem) i Rise (ile sukcesów przed ponownym włączeniem). Projekt wymaga również implementacji Session Persistence (Sticky Sessions) bazującej na źródłowym adresie IP lub cookie HTTP dla utrzymania sesji użytkownika na tym samym serwerze, SSL Termination (rozszyfrowanie SSL na LB dla oszczędności zasobów serwerów backend) oraz fail-over między wieloma urządzeniami LB w konfiguracji Active-Standby dla zapewnienia ciągłości przy awarii samego LB.
Sklep internetowy notuje ponad 10 000 jednoczesnych sesji użytkowników, a pojedynczy serwer WWW (2x CPU, 16 GB RAM) osiąga 100% wykorzystania CPU, powodując kilkusekundowe czasy odpowiedzi i utratę klientów w godzinach szczytu (15:00-21:00). Konieczne jest zaprojektowanie i wdrożenie systemu load balancingu (rozłożenia obciążenia) rozdzielającego ruch HTTP/HTTPS między farmę minimum trzech serwerów WWW (każdy z identyczną zawartością - współdzielone storage NFS/iSCSI lub replikacja), przy czym solution może być implementowana sprzętowo (F5 BIG-IP, Citrix NetScaler) lub programowo (HAProxy, Nginx, software LB w MikroTik). Load Balancer (LB) nasłuchuje na wirtualnym adresie IP (VIP), który jest reklamowany w DNS dla domeny sklepu, a żądania klientów rozdziela na serwery backendowe według wybranego algorytmu: Round Robin (równy podział po kolei) dla serwerów o równej mocy obliczeniowej, Least Connections (najmniej aktywnych połączeń) dla lepszego balansu przy asymetrycznym obciążeniu, lub Weighted Round Robin (z wagami) gdy serwery mają różne parametry. Mechanizm Health Check periodycznie weryfikuje dostępność serwerów backend (np. HTTP GET na /health.html co 5 sekund z oczekiwanym kodem 200), wykluczając niedziałające węzły z puli i automatycznie przywracając je po powrocie do sprawności. Dla zachowania ciągłości sesji użytkowników (np. koszyk zakupowy) konieczna jest konfiguracja Session Persistence (Sticky Sessions) oparta na źródłowym adresie IP (Source IP Hash) lub cookie HTTP (Insert cookie zbalansowanego serwera). Redundancja samego Load Balancera (Active-Standby z heartbeat, VRRP) zapewnia, że awaria urządzenia LB nie spowoduje przerwy w dostępności sklepu. Testowanie musi symulować awarię jednego, dwóch i trzech serwerów backend jednocześnie, weryfikując automatyczne przełączenie i czas reakcji systemu.
- 1. Przygotowanie farmy serwerów (Backend) z identyczną konfiguracją usług.
- 2. Wybór i instalacja oprogramowania/sprzętu Load Balancer (np. HAProxy, MikroTik).
- 3. Konfiguracja adresu Virtual IP (VIP), na którym LB będzie przyjmował ruch.
- 4. Zdefiniowanie puli serwerów (Real Servers) i ich adresów fizycznych.
- 5. Wybór algorytmu rozkładu ruchu (np. Round Robin dla równych serwerów).
- 6. Konfiguracja mechanizmu Health Check (np. odpytywanie portu 80/443 co 5 sek.).
- 7. Implementacja Session Persistence (Sticky Sessions) bazującej na Source IP lub Cookie.
- 8. Konfiguracja progów przełączenia w przypadku braku odpowiedzi z serwera (Fall/Rise).
- 9. Optymalizacja wydajności poprzez SSL Termination na Load Balancerze.
- 10. Konfiguracja powiadomień o awarii poszczególnych węzłów farmy.
- 11. Testowanie scenariusza awarii jednego, dwóch i trzech serwerów naraz.
- 12. Analiza logów LB w celu weryfikacji poprawnego rozkładu połączeń.
- 13. Monitorowanie obciążenia procesora i pamięci na urządzeniu LB.
- 14. Zabezpieczenie panelu zarządzania LB listami ACL.
- Serwery backend muszą mieć IDENTYCZNĄ zawartość - NFS/iSCSI współdzielone lub rsync replication przed podłączeniem LB.
- Wybór algorytmu: Round Robin dla serwerów równej mocy, Least Connections dla różnych, Weighted dla asymetrii.
- Health check: HTTP GET na specific URL (np. /health.html) co 5s - sprawdź kod 200, nie tylko TCP connect.
- Fall=2, Rise=2 - szybka detekcja awarii, szybki powrót. Zbyt duże wartości = długi czas downtime.
- Session persistence: Source IP Hash lub Cookie insert - utrzymuje użytkownika na tym samym serwerze przez sesję.
- SSL termination: rozszyfrowanie na LB oszczędza zasoby serwerów backend - certyfikaty na LB, nie backend.
- Testuj awarię serwera (wyłącz serwer httpd) - weryfikuj że LB wyklucza go z puli i ruch idzie dalej.
- VIP to adres w DNS - klienci łączą się do VIP, LB rozdziela do backend, niewidoczny dla klienta.
- Monitoruj metryki LB: połączenia/sek, wykorzystanie serwerów, kolejki - awaria widoczna w metrykach.
- Redundancja LB: Active-Standby drugiego LB (keepalived/VRRP) - awaria LB nie = awaria usługi.
Dokumentacja powinna zawierać szczegółowe statystyki rozkładu ruchu między serwerami backendowymi z wykorzystaniem poleceń diagnostycznych Load Balancera, pokazujące liczbę połączeń przypadających na każdy serwer (dla algorytmu Round Robin) lub aktualną liczbę połączeń aktywnych (dla algorytmu Least Connections). Wymagane jest przedstawienie wyników testu scenariusza "n-1" polegającego na wyłączeniu jednego, dwóch i trzech serwerów z farmy jednocześnie, z dokumentacją czasu detekcji awarii (detection time), czasu przekierowania ruchu na sprawne serwery oraz wpływu na dostępność usługi mierzonego wskaźnikiem SLA. Dokumentacja musi zawierać analizę opóźnień wprowadzanych przez Load Balancer (latency) z pomiarem czasu odpowiedzi przed i po wprowadzeniu LB do infrastruktury.
Część 3 Ataki L2 (MAC Flooding, ARP Spoofing), Port Security, AP security.
Celem projektu jest zabezpieczenie przełączników i sieci bezprzewodowej przed najpopularniejszymi atakami wewnątrzsieciowymi (L2) wykonywanymi przez użytkowników lub złośliwe oprogramowanie w warstwie dostępu. Projekt obejmuje wdrożenie mechanizmów ochronnych na przełącznikach: Port Security (max. liczba MAC na porcie, akcja shutdown/restrict/protect przy naruszeniu) dla obrony przed atakami MAC Flooding/CAM Table Overflow; DHCP Snooping (zbudowanie tabeli powiązań IP-MAC-Port-VLAN na portach nieufnych i filtrowanie odpowiedzi DHCP od nieautoryzowanych serwerów) dla obrony przed atakami Rogue DHCP Server i DHCP Starvation; Dynamic ARP Inspection (DAI) - walidacja pakietów ARP względem tabeli DHCP Snooping binding, filtrowanie nieprawidłowych odpowiedzi ARP dla obrony przed atakami ARP Spoofing/MITM; IP Source Guard - blokowanie ruchu na portach nieufnych gdy źródłowy adres IP nie jest w tabeli DHCP Snooping. Kluczowym elementem jest również konfiguracja sieci bezprzewodowej z wykorzystaniem WPA3 Enterprise lub WPA2 Enterprise z serwerem RADIUS, VLAN per SSID, MAC Filtering oraz separacją ruchu (guest isolation). Projekt wymaga również rozważenia IEEE 802.1X z wykorzystaniem serwera RADIUS (FreeRADIUS, Cisco ISE) dla autentykacji użytkowników przed udostępnieniem portu oraz implementacji Protected Port (Private VLAN Edge) dla izolacji portów dostępowych od siebie nawzajem.
W sieci korporacyjnej wykryto anomalie wskazujące na próby ataków man-in-the-middle (MITM) - użytkownicy zgłaszają, że widzą w arkuszu ARP (arp -a) nietypowe wpisy z dublującymi się adresami MAC dla bramy domyślnej, a analizator sniffer wykazał obecność nieautoryzowanych odpowiedzi ARP na portach dostępowych. Dodatkowo, przełącznik dostępowy zgłasza przepełnienie tablicy CAM (CAM Table Overflow) - tysiące dynamicznie wyuczonych adresów MAC powodują, że nowe wpisy nie są dodawane, a ruch broadcast/multicast wzrósł trzykrotnie. Analiza wykazała, że ataki pochodzą z portów dostępowych w których użytkownicy mogą swobodnie podłączać własne urządzenia (laptopy, tablety) bez jakichkolwiek zabezpieczeń. Konieczne jest wdrożenie wielowarstwowego systemu ochrony warstwy 2 na przełącznikach: Port Security z maksymalnie 1-2 dozwolonymi adresami MAC na port i akcją shutdown w przypadku naruszenia; DHCP Snooping budujący tabelę binding (IP-MAC-Port-VLAN) na portach nieufnych i blokujący odpowiedzi DHCP od nieautoryzowanych serwerów; Dynamic ARP Inspection (DAI) walidujący każdy pakiet ARP względem tabeli DHCP Snooping i blokujący fałszywe odpowiedzi ARP; IP Source Guard blokujący pakiety IP, których źródłowy adres nie jest w tabeli binding. Porty uplink do przełączników nadrzędnych i serwerów DHCP muszą być oznaczone jako trusted, natomiast wszystkie porty dostępowe jako untrusted. Zabezpieczenia STP (BPDU Guard na portach brzegowych, Root Guard na portach do przełączników równorzędnych) chronią przed atakami polegającymi na wysłaniu BPDU z niższym priorytetem, co mogłoby przejąć rolę Root Bridge. Sieć bezprzewodowa wymaga wdrożenia WPA3 Enterprise z serwerem RADIUS (FreeRADIUS) dla silnej autentykacji użytkowników oraz izolacji ruchu między klientami (Client Isolation/Guest Isolation). Po wdrożeniu konieczne jest przeprowadzenie testów penetracyjnych z wykorzystaniem narzędzi typu Yersinia, Scapy lub ettercap w celu symulacji ataków i weryfikacji skuteczności zabezpieczeń.
- 1. Inwentaryzacja portów dostępowych i wyłączenie wszystkich nieużywanych (shutdown).
- 2. Konfiguracja Port Security na portach użytkowników (maximum 1-2 MAC).
- 3. Włączenie zapamiętywania adresów MAC funkcją Sticky MAC.
- 4. Konfiguracja akcji naruszenia (violation) na "restrict" lub "shutdown".
- 5. Globalna aktywacja funkcji DHCP Snooping dla wybranych VLAN-ów.
- 6. Wyznaczenie portów zaufanych (trusted) dla połączeń z serwerem DHCP.
- 7. Inicjalizacja Dynamic ARP Inspection (DAI) w celu blokowania ARP Spoofing.
- 8. Konfiguracja IP Source Guard w celu powiązania adresu IP z adresem MAC i portem.
- 9. Implementacja ochrony przed BPDU Spoofing (BPDU Guard) na portach brzegowych.
- 10. Konfiguracja Root Guard na portach prowadzących do innych przełączników.
- 11. Testowanie zabezpieczeń poprzez próbę podłączenia nieautoryzowanego hosta.
- 12. Analiza logów przełącznika pod kątem komunikatów o naruszeniach bezpieczeństwa.
- 13. Weryfikacja bazy wiązań DHCP (show ip dhcp snooping binding).
- 14. Zarządzanie dostępem Wi-Fi przez silne szyfrowanie WPA3 Enterprise.
- Włącz Port Security na każdym porcie dostępowym - max 1-2 adresy MAC, akcja shutdown.
- sticky MAC: automatycznie zapamiętuje podłączony MAC - nie wymaga ręcznej konfiguracji na każdym porcie.
- DHCP Snooping włącz na VLAN z użytkownikami - buduje bazę binding (IP-MAC-Port-VLAN).
- Port do routera/DHCP = trusted - tylko tam odpowiedzi DHCP, reszta untrusted blokuje rogue serwery.
- DAI wymaga DHCP Snooping - walidacja ARP względem bazy binding, blokuj ARP spoofing.
- IP Source Guard: blokuje pakiety z IP spoza binding - jak ktoś ręcznie ustawi IP innego.
- BPDU Guard na portach dostępowych - blokuje ataki STP (podłączenie nieautoryzowanego switcha).
- Root Guard na portach do innych przełączników - zapobiega przejęciu roli Root Bridge przez nieautoryzowany switch.
- Wireshark pokaże ataki ARP spoofing - weryfikuj że DAI blokuje fałszywe odpowiedzi.
- Regularnie sprawdzaj logi: "show port-security violations", "show ip dhcp snooping binding" - audyt bezpieczeństwa.
Dokumentacja powinna zawierać szczegółowy opis mechanizmu działania każdego wdrożonego zabezpieczenia warstwy 2 wraz z uzasadnieniem wybranych parametrów konfiguracyjnych (np. dlaczego Port Security max 1 MAC, dlaczego akcja shutdown zamiast restrict). Wymagane jest przedstawienie logów z przełącznika zarejestrowanych podczas próby ataku, obejmujących komunikaty o naruszeniu Port Security (SHUTDOWN or RESTRICT), logi DHCP Snooping z wykryciem nieautoryzowanego serwera DHCP oraz logi DAI z blokadą fałszywych odpowiedzi ARP. Dokumentacja musi zawierać weryfikację bazy "binding" dla DHCP Snooping (tabela powiązań IP-MAC-Port-VLAN) z polecenia show ip dhcp snooping binding, pokazującą prawidłowo zbudowaną bazę dozwolonych urządzeń.

Część 5 VPN Koncentratory, tunelowanie, prywatność danych.
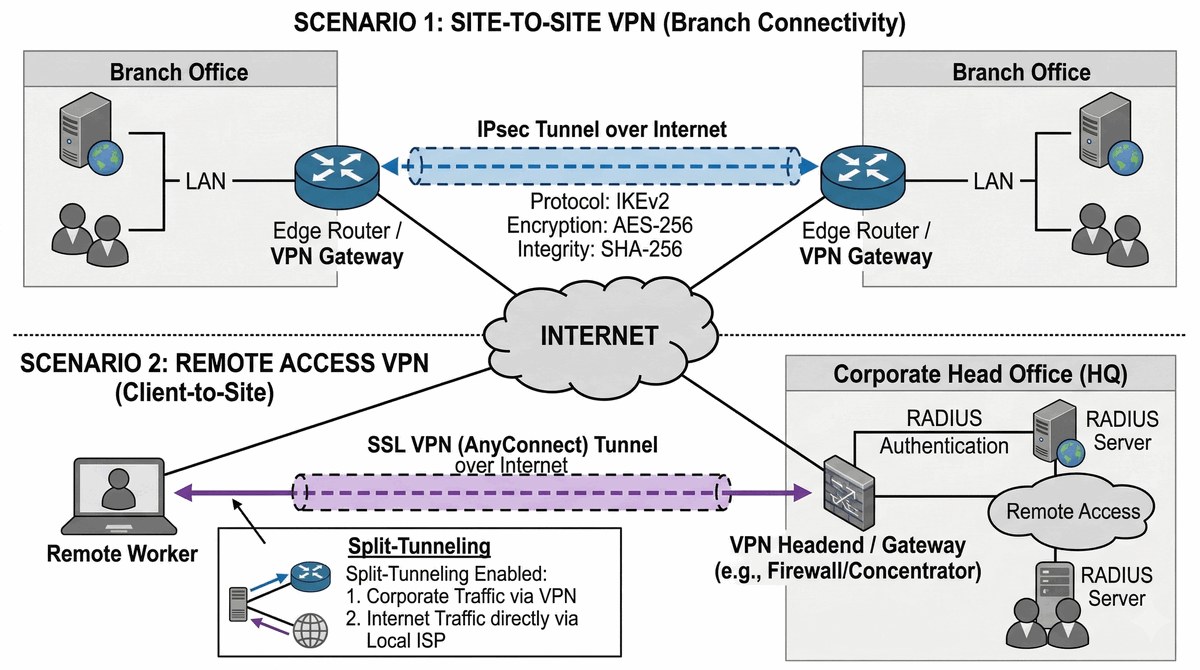
Celem projektu jest zapewnienie bezpiecznej komunikacji między oddziałami firmy (Site-to-Site) poprzez szyfrowane tunele VPN oraz umożliwienie zdalnego dostępu (Remote Access VPN) dla pracowników pracujących poza biurem. Projekt obejmuje konfigurację tuneli IPsec w trybie IKEv2 (zalecany w 2025/2026, oferuje lepszą odporność na ataki i szybszą negocjację niż IKEv1) z wykorzystaniem algorytmów kryptograficznych: AES-GCM-256 do szyfrowania, ECDH groups 19/20/21 dla wymiany kluczy (zamiast przestarzałego DH group 14/5), SHA-256 lub SHA-3 dla integralności. Kluczowym elementem jest implementacja Site-to-Site VPN w modelu policy-based (Crypto ACL) lub route-based (VTI - Virtual Tunnel Interface) w zależności od skali - mniejsze wdrożenia = policy-based, większe lub z routingiem dynamicznym = route-based. Dla Remote Access VPN wymagana jest konfiguracja SSL VPN (Cisco AnyConnect/OpenConnect lub inny klient) lub IPsec IKEv2 z odpowiednim profilem połączenia, pulą adresów IP oraz autentykacji (lokalna baza użytkowników lub RADIUS). Projekt wymaga również zarządzania certyfikatami lub PSK (Pre-Shared Key), konfiguracji transform set/proposal (ESP-AES-256-GCM, ESP-SHA256-HMAC), NAT-Traversal dla obsługi za NAT oraz testowania łączności i failover w przypadku utraty tunelu.
Firma otwiera nowy oddział w mieście B oddalonym o 250 km od centrali w mieście A, a pracownicy terenowi (Handlowcy, serwisanci) pracują z domów i hoteli i wymagają stałego dostępu do wewnętrznych zasobów (CRM, pliki, wewnętrzne aplikacje WEB). Przekaz danych przez publiczny Internet bez szyfrowania jest nieakceptowalny ze względów bezpieczeństwa (RODO, PCI-DSS dla danych klientów), dlatego konieczne jest zestawienie szyfrowanego tunelu VPN Site-to-Site IPsec między ruterami brzegowymi obu lokalizacji, zapewniającego poufność, integralność i autentykację całego ruchu między oddziałami. Tunel IPsec w trybie IKEv2 (zalecany w 2025/2026 ze względu na lepszą odporność na ataki i szybszą negocjację niż IKEv1) wykorzystuje algorytmy kryptograficzne: AES-256-GCM do szyfrowania danych (ESP), SHA-256 do integralności (HMAC), oraz grupę DH 14 (3072-bit) lub wyżej do wymiany kluczy sesyjnych. Konfiguracja realizowana jest w modelu policy-based (Crypto ACL definiująca ruch "interesting" do zaszyfrowania) lub route-based (VTI - Virtual Tunnel Interface z routingiem protokołem OSPF/BGP przez tunel) w zależności od topologii i wymagań. Dla pracowników zdalnych (Remote Access) wymagana jest brama SSL VPN (Cisco AnyConnect, OpenConnect, lub funkcja SSL VPN w ruterze) z autentykacją dwuskładnikową lub integracją z Active Directory przez RADIUS, pulą adresów IP dla klientów (np. 10.255.0.0/24) oraz opcjonalnym split-tunnelingiem pozwalającym na dostęp tylko do zasobów firmowych (ruchu do Internetu przez lokalne łącze użytkownika). NAT-Traversal musi być włączony dla obsługi klientów pracujących za NATem domowym/routerem mobilnym. Testowanie obejmuje weryfikację szyfrowania (analiza pakietów w Wireshark - brak tekstu jawnego), pomiar przepustowości tunelu oraz symulację utraty łącza i automatycznego nawiązania sesji (rekey).
- 1. Ustalenie parametrów fazy 1 IKEv2 (ISAKMP): algorytm szyfrowania, haszowania i grupa DH.
- 2. Konfiguracja klucza współdzielonego (Pre-Shared Key) lub certyfikatów RSA.
- 3. Zdefiniowanie parametrów fazy 2 (IPsec Transform Set) - ESP-AES-256 i ESP-SHA-HMAC.
- 4. Stworzenie listy ACL definiującej ruch do zaszyfrowania (Interesting Traffic).
- 5. Konfiguracja Crypto Map i powiązanie jej z interfejsem wychodzącym WAN.
- 6. Inicjalizacja VPN SSL (AnyConnect) na koncentratorze VPN/Routerze.
- 7. Przygotowanie puli adresów IP dla klientów zdalnych (VPN Pool).
- 8. Konfiguracja mechanizmów autentykacji (lokalna baza, RADIUS lub LDAP).
- 9. Umożliwienie mechanizmu Split-Tunneling w celu optymalizacji pasma użytkownika.
- 10. Weryfikacja stanu tunelu Site-to-Site poleceniem "show crypto ipsec sa".
- 11. Testowanie łączności (Ping) między hostami w różnych oddziałach.
- 12. Analiza pakietów w celu potwierdzenia szyfrowania ruchu (brak tekstu jawnego).
- 13. Konfiguracja redundantnych tuneli VPN w przypadku posiadania dwóch linków WAN.
- 14. Sporządzenie protokołu z testów bezpieczeństwa i dostępności tunelu.
- IKEv2 z AES-256-GCM i SHA-256 - 2026 minimum bezpieczeństwa, IKEv1 deprecated.
- Grupa DH 14 lub wyższa - DH 5 za słaba, minimum 3072-bit (grupa 14/15/16).
- PSK lub certyfikaty RSA - certyfikaty bezpieczniejsze przy skali, PSK prościej w małych wdrożeniach.
- Crypto ACL (policy-based) lub VTI (route-based) - mniejsze sieci = policy, większe/routing dynamiczny = VTI.
- test "show crypto ipsec sa" - weryfikuj encap/decap packets = tunnel działa, brak = problem.
- Wireshark: próbki ESP, brak plaintext = szyfrowanie działa, widzisz plaintext = problem.
- SSL VPN: AnyConnect/OpenConnect - certyfikaty po stronie serwera, hasło lub 2FA użytkownika.
- VPN Pool: osobna podsieć np. 10.255.0.0/24 - nie nachodzi na sieci wewnętrzne, uniknij overlap.
- Split-tunneling: tylko ruch do firmy przez VPN - oszczędza pasmo użytkownika, ruch do internetu lokalnie.
Dokumentacja powinna zawierać szczegółową analizę nagłówka pakietu IPsec z przechwyconego ruchu w programie Wireshark, wyraźnie pokazującą obecność protokołu ESP (Encapsulating Security Payload) z numerem SPI (Security Parameter Index), numerami sekwencyjnymi oraz zaszyfrowaną zawartością (brak tekstu jawnego w polu danych). Wymagane jest przeprowadzenie testów przepustowości tunelu VPN z wykorzystaniem narzędzi iperf lub speedtest, z porównaniem wyników przed i po zestawieniu tunelu, uwzględniając narzut (overhead) szyfrowania. Dokumentacja musi zawierać szczegółową konfigurację klienta VPN (np. Cisco AnyConnect, OpenConnect, Shrew Client) z wszystkimi parametrami profilu połączenia, w tym adresem serwera, metodą autentykacji, wybranymi algorytmami kryptograficznymi oraz opcjami split-tunnelingu.
Część 5 Zarządzanie siecią, monitorowanie, urządzenia wspomagające.
Celem projektu jest wdrożenie kompletnego systemu nadzoru nad infrastrukturą sieciową w celu szybkiej diagnostyki awarii, planowania pojemności (Capacity Planning) i optymalizacji wydajności. Projekt obejmuje konfigurację platformy monitorującej (NMS - Network Management System) takiej jak Zabbix, PRTG, LibreNMS lub Cisco DNA Center z agentami/enkapsulatorami SNMP na urządzeniach sieciowych. Kluczowym elementem jest konfiguracja SNMP (Simple Network Management Protocol) w wersji v2c (community string, bezpieczeństwo umiarkowane) lub v3 (SHA-256/AES-256, pełne bezpieczeństwo z autentykacją i szyfrowaniem dla środowisk produkcyjnych) dla zbierania metryk: IF-MIB (wykorzystanie interfejsów), CPU-MIB (obciążenie CPU), Memory-MIB (wykorzystanie pamięci), entPhysicalEntry (stan portów). Wymagana jest konfiguracja SNMP Traps dla alertów asynchronicznych (linkDown, linkUp, cpuHigh, environmental alerts) wysyłanych do NMS. Projekt obejmuje również konfigurację Syslog (System Logging Protocol) dla centralizacji logów z urządzeń sieciowych do serwera syslog (rsyslog, Kiwi Syslog, Graylog) z klasyfikacją severity (0-6) oraz konfigurację NetFlow/IPFIX lub sFlow dla analizy przepływów ruchu - identyfikacji "kto ile" i "co" konsumuje pasmo (Top Talkers, Top Applications). Wymagane jest utworzenie dashboardów, progów alertów (thresholds) i raportów dziennych/tygodniowych.
Administratorzy sieci otrzymują telefoniczne zgłoszenia od użytkowników o "wolnej sieci" w godzinach popołudniowych (14:00-18:00), ale nie mają żadnych obiektywnych danych potwierdzających przyczynę - nie wiedzą, który segment sieci jest przeciążony, które aplikacje generują największy ruch, ani kiedy dokładnie problem się pojawia. Dodatkowo, awaria przełącznika dostępowego na drugim piętrze została wykryta dopiero po 3 godzinach, ponieważ nikt nie był fizycznie obecny w budynku, a stacje robocze automatycznie przeszły na zapasowy WLAN bez powiadomienia NOC. Konieczne jest wdrożenie kompletnego systemu monitorowania sieci opartego na trzech filarach: protokole SNMP (Simple Network Management Protocol) w wersji 3 (z autentykacją SHA i szyfrowaniem AES-256) zbierającym metryki z wszystkich urządzeń sieciowych (wykorzystanie CPU, pamięci, portów Gigabit - IF-MIB, CPU-MIB, entPhysicalEntry) do platformy NMS (Zabbix, PRTG, LibreNMS) w interwale co 1-5 minut z dashboardami pokazującymi status w czasie rzeczywistym; protokole Syslog направляjącym logi z urządzeń (autentykacja, ACL denied, link Up/Down, błędy interfejsów) do centralnego serwera (rsyslog, Graylog) z klasyfikacją severity (0-Emergency do 6-Debug) i możliwością wyszukiwania pełnotekstowego; protokole NetFlow/IPFIX lub sFlow analizującym przepływy ruchu (source IP, destination IP, port, bytes, packets) w celu identyfikacji Top Talkers (kto generuje najwięcej ruchu) i Top Applications (które usługi/porty dominują). Konfiguracja progów alertowych (thresholds) musi generować powiadomienia (e-mail, SMS, webhook do Slack) gdy wykorzystanie CPU przekracza 80%, pamięć >85%, interfejs >90% przepustowości, lub gdy nastąpi zdarzenie linkDown. SNMP Traps zapewniają asynchroniczne powiadomienia o awariach (coldStart, warmStart, linkDown, linkUp). Dokumentacja projektu musi zawierać screenshoty dashboardów, wyniki analizy przepływów NetFlow w godzinach szczytu wskazujące źródło problemu oraz raport zdarzeń krytycznych za minimum 7 dni.
- 1. Wybór platformy monitorującej (np. Zabbix) i jej instalacja w dedykowanym VLANie.
- 2. Konfiguracja SNMPv3 na wszystkich urządzeniach (User, Group, Privacy, Auth).
- 3. Włączenie eksportu NetFlow/IPFIX na ruterach brzegowych i Core.
- 4. Konfiguracja adresu docelowego kolektora NetFlow (Flow Exporter).
- 5. Centralizacja zbierania logów poprzez wskazanie serwera Syslog.
- 6. Ustalenie poziomu logowania (Logging Level) na "Informational" lub "Warning".
- 7. Definiowanie progów alarmowych (Triggers) dla zajętości CPU (>80%) i pamięci.
- 8. Konfiguracja SNMP Traps dla zdarzeń krytycznych (np. Link Down/Up).
- 9. Tworzenie map topologii sieci w systemie monitoringu.
- 10. Konfiguracja dashboardów prezentujących ruch na kluczowych interfejsach.
- 11. Analiza przepływów (Flows) w celu identyfikacji aplikacji pożerających pasmo.
- 12. Testowanie powiadomień (e-mail/SMS/Slack) po symulowanej awarii łącza.
- 13. Archiwizacja i cykliczny przegląd logów systemowych pod kątem błędów sprzętowych.
- 14. Optymalizacja częstotliwości odpytywania (Polling Interval) urządzeń.
- SNMPv3 z auth SHA + priv AES - v2c nie ma autentykacji/szyfrowania, niezgodne z 2026.
- Community string NIGDY w postaci plaintext - v3 user/key lokalnie lub AAA RADIUS.
- PollingInterval: CPU/memory co 1-5min - za często = obciążenie, za rzadko = opóźnienie alertów.
- Zabbix/PRTG/LibreNMS: dodaj urządzenia po IP, SNMP profiles dla vendor/model - automatyzacja templatami.
- SNMP Traps: linkDown/linkUp, coldStart, authFailure - wysyłaj do NMS na porcie 162/UDP.
- Syslog do serwera: rsyslog/Graylog na dedykowanym VLAN - izoluj od ruchu użytkownika.
- Severity: 0-3 = krytyczne do alertu, 4-6 = logowanie - filtrowanie istotnych zdarzeń.
- NetFlow/IPFIX: exporter na routerach, collector na serwerze - 2055/UDP domyślnie.
- Przeanalizuj flows: Top Talkers (kto), Top Apps (co) - co zużywa pasmo w godzinach szczytu.
- Triggery: CPU>80%, memory>85%, interface>90% - alert email/SMS/Slack.
Dokumentacja powinna zawierać zrzuty ekranu z dashboardów platformy monitorującej (np. Zabbix, PRTG, LibreNMS) prezentujących status wszystkich urządzeń sieciowych, wykorzystanie CPU i pamięci, wykorzystanie pasma na kluczowych interfejsach oraz historię zdarzeń. Wymagana jest analiza wyników przepływów NetFlow w godzinach szczytu (14:00-18:00) identyfikująca "Top Talkers" (adresy IP lub hosty generujące największy ruch) oraz "Top Applications" (protokoły lub porty dominujące w wykorzystaniu pasma, np. HTTP/HTTPS, SMB, streaming). Dokumentacja musi zawierać wykaz zdarzeń krytycznych z logów systemowych obejmujący wszystkie incydenty z poziomem severity Error (3) lub Critical (2) w okresie testowym, wraz z czasem detekcji i czasem rozwiązania (MTTR - Mean Time To Resolve).
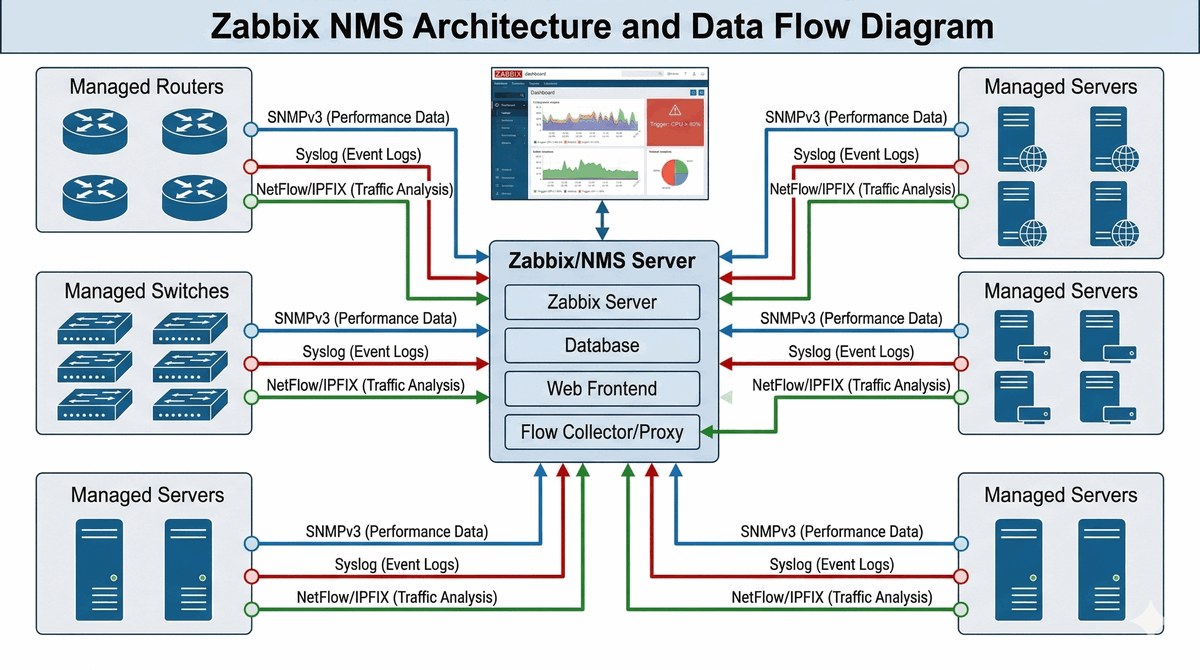
Część 1-5 Całość materiału wykładowego.
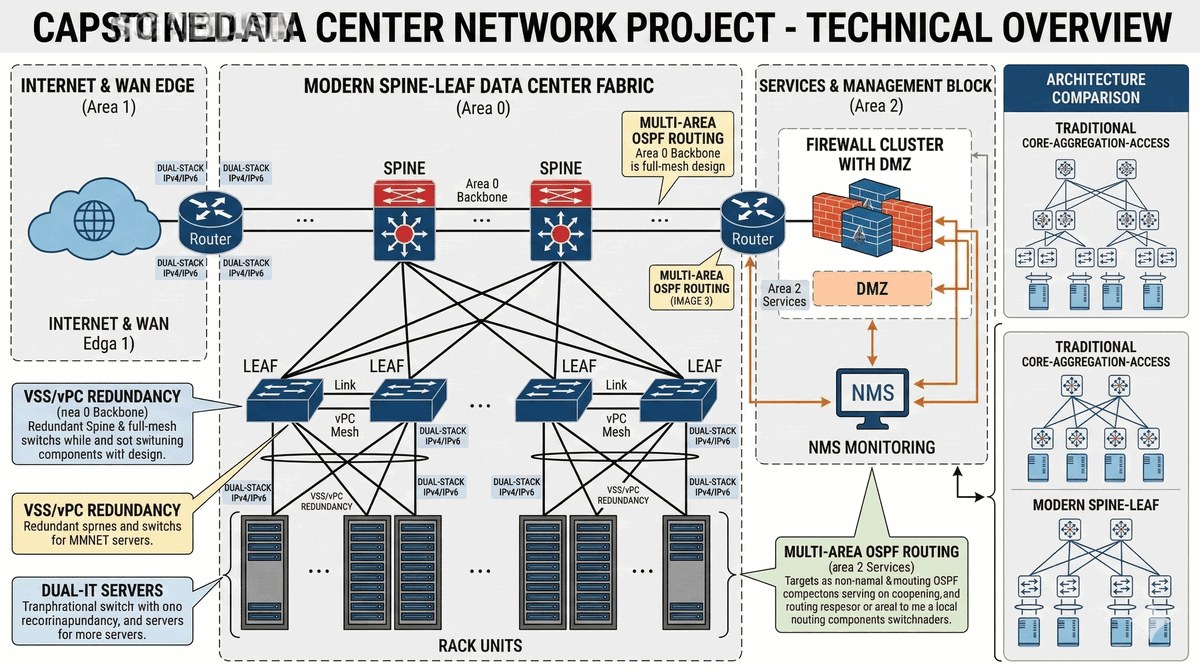
Celem projektu jest stworzenie kompleksowego projektu sieciowego nowoczesnego Data Center łączącego wszystkie aspekty kursu: od fizycznego medium transmisyjnego, przez wysokodostępny szkielet (fabric) warstwy 2 i 3, po bezpieczeństwo i usługi wyższych warstw - zadanie integrujące (Capstone). Projekt obejmuje zaprojektowanie topologii Spine-Leaf (obecnie standard przemysłowy zastępujący przestarzały trójwarstwowy model Core-Distribution-Access) z wykorzystaniem przełączników ToR (Top-of-Rack) jako Leaf i switchy centralne jako Spine, połączonych redundantnymi łączami 100G/200G/400G z oversubscription ratio dopasowanym do klasy obciążenia (np. 3:1 dla typowych obciążeń, 1.5:1 dla AI/ML). Kluczowym elementem jest implementacja VXLAN (Virtual Extensible LAN) z EVPN jako kontrolą warstwy overlay dla skalowalności (obsługa tysięcy VLAN w multi-tenant) lub tradycyjnego L2 z MSTP i L3 z OSPF/ECMP. Wymagany jest redundantny szkielet L2 z EtherChannel (LACP) dla trunków między Leaf, routing L3 z OSPF lub BGP dla łączności między podsieciami, brzeg sieci z NAT/PAT, ACL i opcjonalnym firewallem, obsługa Dual-Stack IPv4/IPv6 oraz integracja systemu monitorowania (SNMP/Syslog/NetFlow). Projekt wymaga również dokumentacji schematu fizycznego i logicznego, tabeli adresacji, specyfikacji sprzętowej z redundantnym zasilaniem i chłodzeniem, oraz analizy przepustowości uplinków z uwzględnieniem congestion i fail-over.
Firma planuje budowę nowoczesnego Data Center (DC) Tier III (99,982% dostępności rocznej) o powierzchni około 500 m² z docelową mocą obliczeniową 100 kW, zdolnego do obsługi 200 serwerów fizycznych, 50 maszyn wirtualnych na hiperwizorach (VMware ESXi) oraz infrastruktury kontenerowej (Kubernetes). Projekt sieci DC musi integrować wszystkie technologie omawiane w kursie w spójną, kompleksową architekturę obsługującą typowe obciążenia (WWW, bazy danych PostgreSQL/MySQL, NFS storage, backup) oraz obciążenia wymagające niskich opóźnień (bazy danych Redis, HPC). Topologia fizyczna oparta jest na modelu Spine-Leaf (zastępującym przestarzały trójwarstwowy Core-Distribution-Access) z przełącznikami ToR (Top-of-Rack) jako Leaf połączonymi redundantnie do minimum dwóch przełączników Spine (każdy Spine ma minimum 16 portów 100/400 GbE) z wykorzystaniem kabli DAC (Direct Attach Copper) lub światłowodów LC dla połączeń intra-rack i inter-rack. Warstwa L2 (VLAN, MSTP) zapewnia segmentację ruchu między tenantami (np. VLAN 100 dla klienta A, VLAN 200 dla klienta B) oraz redundantną łączność wewnątrz DC, z agregacją EtherChannel (LACP) na trunkach między Leaf a Spine dla pasma minimum 2x100 Gbps. Warstwa L3 (routing) realizowana przez OSPF z szybkim failover (ECMP między Spine'ami) lub BGP dla większych skal (ponad 10 leaf switchy), z sumaryzacją tras na brzegach i pasywnymi interfejsami na portach serwerowych. Brzeg DC z NAT/PAT dla translacji adresów tenantów na publiczne IP DC, Stateful Firewall z ACL dla izolacji segmentów, opcjonalnie moduł IPS/IDS dla inspekcji ruchu między strefami. Stos Dual-Stack IPv4/IPv6 na wszystkich urządzeniach sieciowych z autokonfiguracją SLAAC dla hostów i OSPFv3 dla routingu IPv6. System monitorowania (SNMPv3, Syslog, NetFlow) zintegrowany z istniejącym NMS. Utwardzanie bezpieczeństwa urządzeń obejmuje AAA (RADIUS/TACACS+), SSHv2-only (wyłączenie Telnet), Port Security, DHCP Snooping, DAI. Dokumentacja musi zawierać fizyczny plan rozmieszczenia urządzeń w rackach (schemat rack elevation view), schemat logiczny topologii, tabelę adresacji IPv4/IPv6 wszystkich urządzeń i serwerów, specyfikację sprzętową z redundantnym zasilaniem PDU i UPS, analizę przepustowości uplinków z oversubscription ratio (np. 3:1 dla typowych obciążeń), oraz raport z testów akceptacyjnych (UAT) obejmujący failover, throughput i latency.
- 1. Opracowanie kompletnego schematu logicznego DC (Spine-Leaf lub Core-Agg-Access).
- 2. Dobór specyfikacji sprzętowej uwzględniającej redundancję zasilania i chłodzenia.
- 3. Fizyczna instalacja urządzeń w szafach rack zgodnie ze standardami.
- 4. Implementacja redundantnego szkieletu L2 z wykorzystaniem vPC lub VSS.
- 5. Konfiguracja skalowalnego routingu OSPF z agregacją tras między budynkami.
- 6. Wdrożenie bezpiecznego brzegu sieci z systemami IDS/IPS i Firewallami.
- 7. Konfiguracja stosu Dual-Stack IPv4/IPv6 dla wszystkich usług DC.
- 8. Implementacja mechanizmów QoS dla priorytetyzacji ruchu storage i głosowego.
- 9. Wdrożenie kompletnego systemu monitoringu i raportowania (Dashboarding).
- 10. Utwardzenie bezpieczeństwa urządzeń (AAA, SSH, Port Security).
- 11. Wykonanie kompleksowych testów wydajnościowych i obciążeniowych (Iperf/Traffic Gen).
- 12. Przeprowadzenie audytu bezpieczeństwa i testów penetracyjnych.
- 13. Skonsolidowanie konfiguracji i przygotowanie dokumentacji technicznej >30 stron.
- 14. Finalna prezentacja projektu i obrona wybranych rozwiązań inżynierskich.
- Spine-Leaf: każdy Leaf połączony do MINIMUM 2 Spine - redundancy bez single point of failure.
- VXLAN/EVPN lub L2+L3: VXLAN+EVPN dla multi-tenant, tradycyjne L2 dla mniejszych DC.
- vPC/VSS na uplinkach Leaf-Spine - 2x 100G, jak jeden padnie to drugi przejmuje.
- OSPF/BGP dla L3: ECMP = równoważenie obciążenia między wieloma Spine'ami.
- Dual-Stack: IPv4 + IPv6 na wszystkich urządzeniach - wsparcie od vendor, testuj oba stosy.
- Firewalle/strefy izolujące: tenant VLAN, ACL, NAT dla każdego klienta - bezpieczeństwo.
- QoS: Voice/storage priorities - FC (Fibre Channel) wymaga niskich opóźnień.
- SNMP/Syslog/NetFlow: NMS zbiera metryki z wszystkich urządzeń - unified monitoring.
- AAA: RADIUS/TACACS+ dla zarządzania - rozróżnienie uprawnień admin/operator/inżynier.
- Testy UAT: L2/L3 connectivity, failover, throughput/iperf, penetration test - dokumentacja.
Projekt wymaga przygotowania kompleksowego schematu logicznego Data Center z topologią Spine-Leaf, uwzględniającego wszystkie urządzenia (Spine, Leaf, ToR), połączenia między nimi, przepływy ruchu oraz strefy bezpieczeństwa. Niezbędne jest przedstawienie pełnej tabeli adresacji obejmującej adresy IP zarządzania wszystkich urządzeń, adresy IP interfejsów Loopback, adresy serwerów i usług, adresy VIP dla mechanizmów redundancji oraz adresację IPv6. Dokumentacja musi zawierać skonsolidowany raport z testów akceptacyjnych (UAT - User Acceptance Test) obejmujący wyniki testów łączności L2 i L3, testy failover, testy wydajnościowe (throughput, latency, packet loss) oraz wyniki audytu bezpieczeństwa z testów penetracyjnych przeprowadzonych w celu weryfikacji skuteczności zastosowanych mechanizmów ochronnych.