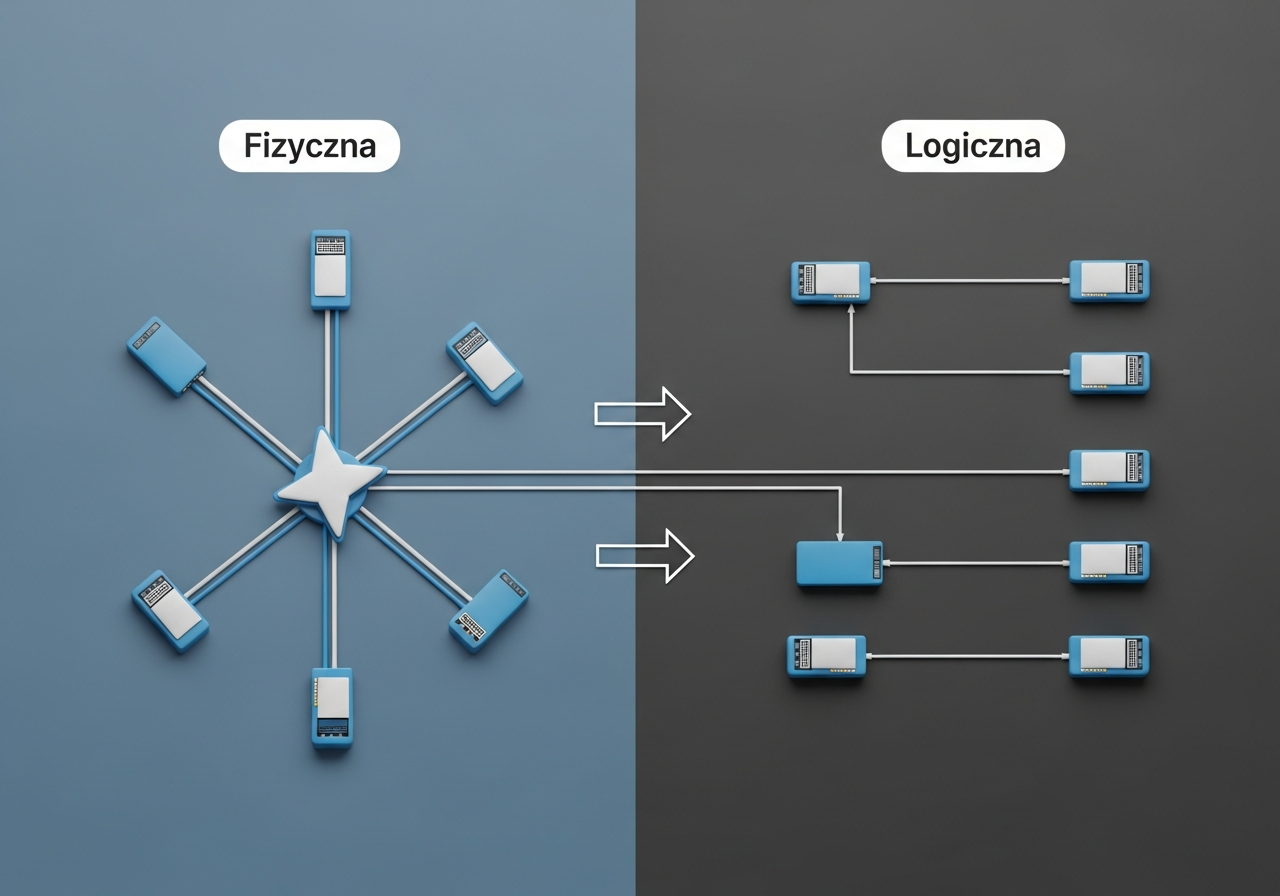
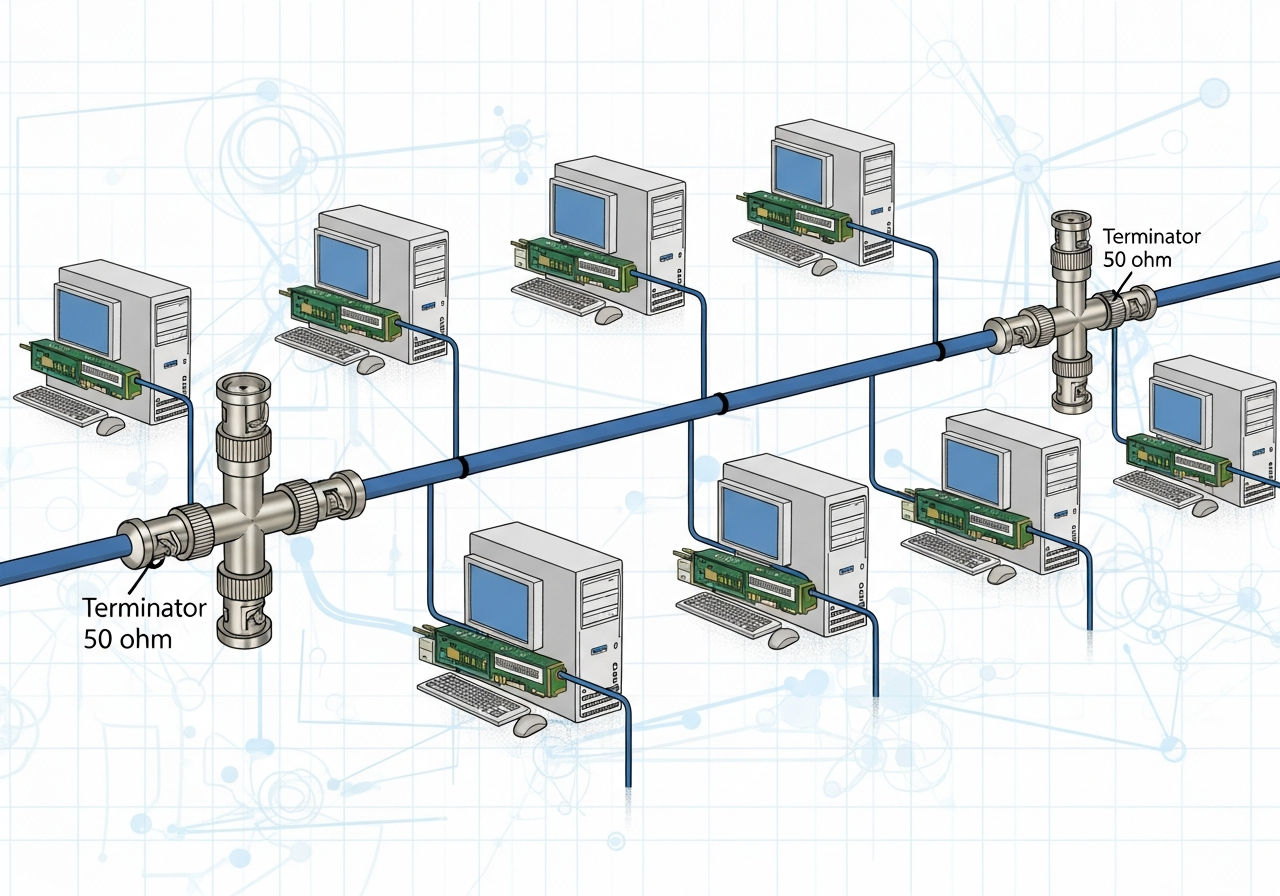
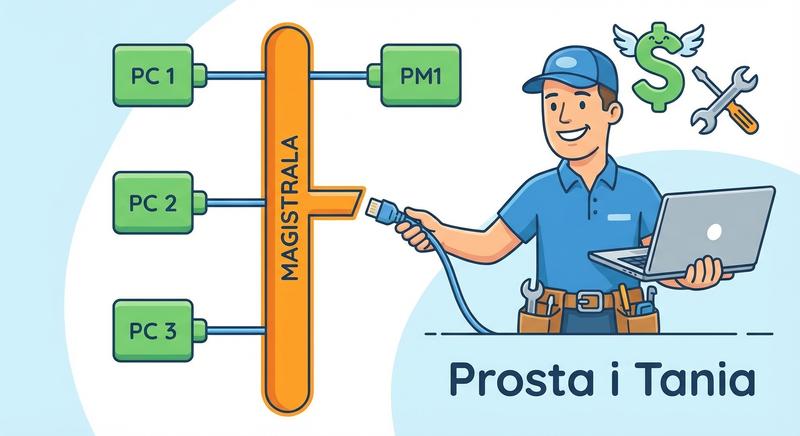
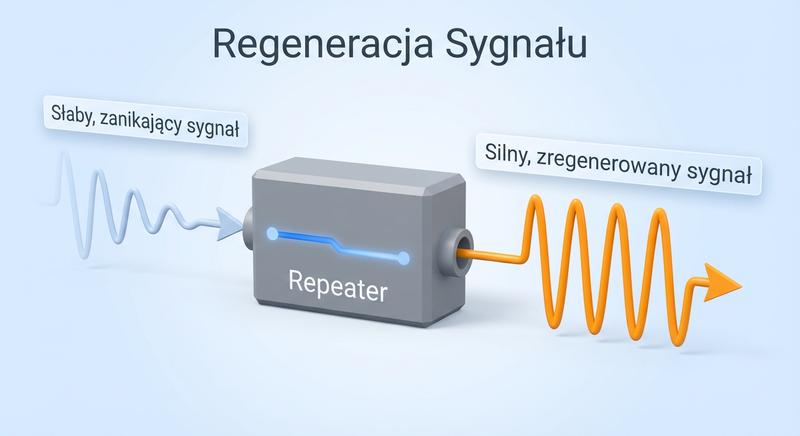
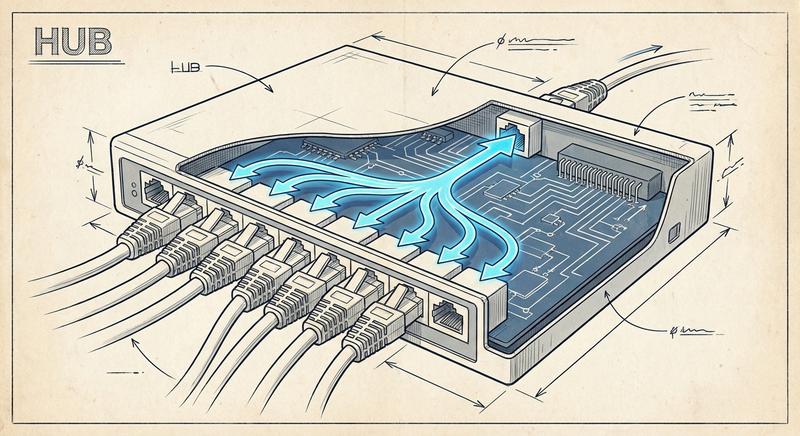
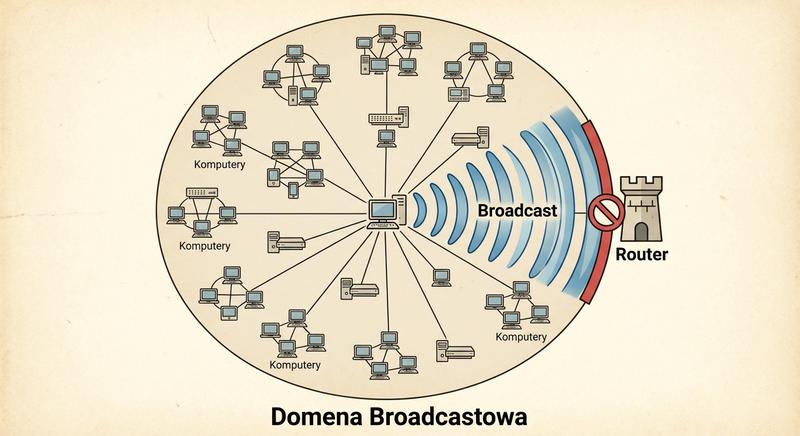
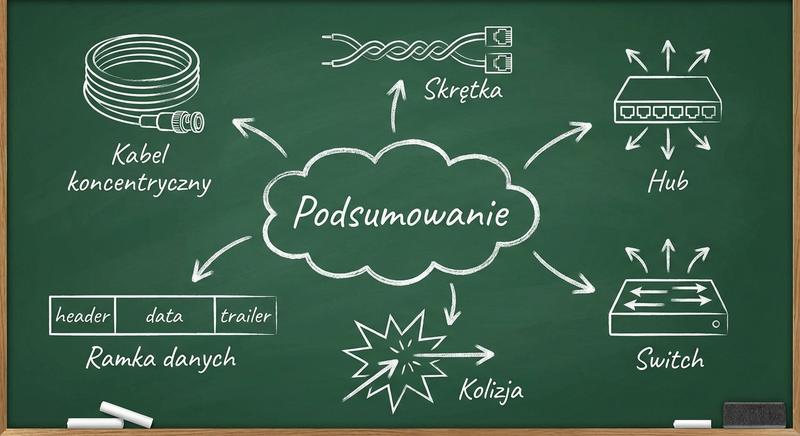
Witam Państwa na pierwszym wykładzie!
Zaczniemy od samych podstaw, cofając się do lat 70. XX wieku, aby zrozumieć, jak narodziła się technologia stanowiąca dziś kręgosłup globalnej komunikacji – sieć Ethernet. Celem tego kursu jest zbudowanie solidnych fundamentów – od historycznych korzeni po praktyczną konfigurację współczesnych urządzeń. Proszę nie obawiać się zadawania pytań – jesteśmy tu, aby wspólnie zgłębiać tajniki IT.