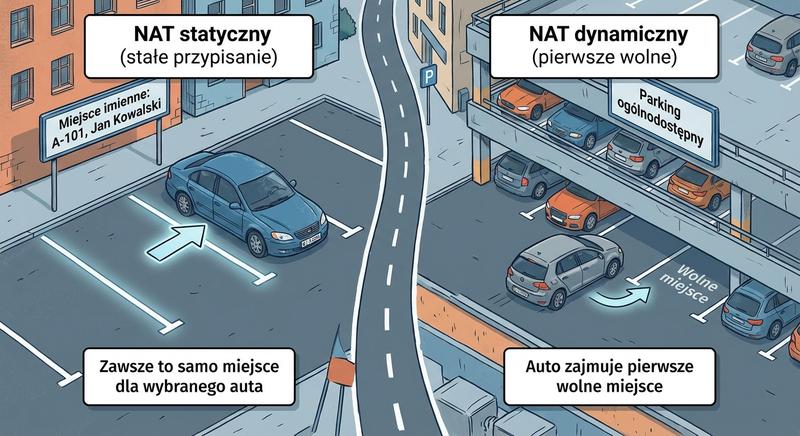
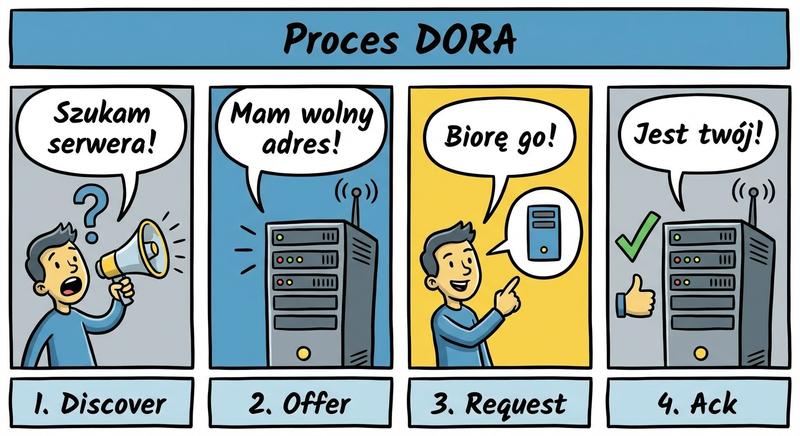
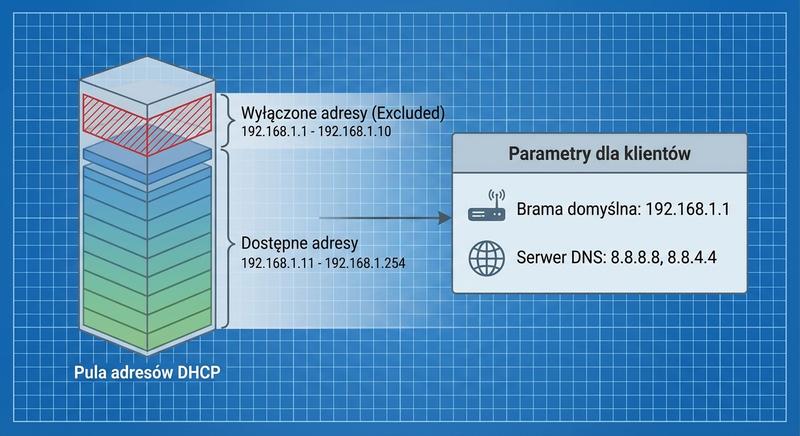
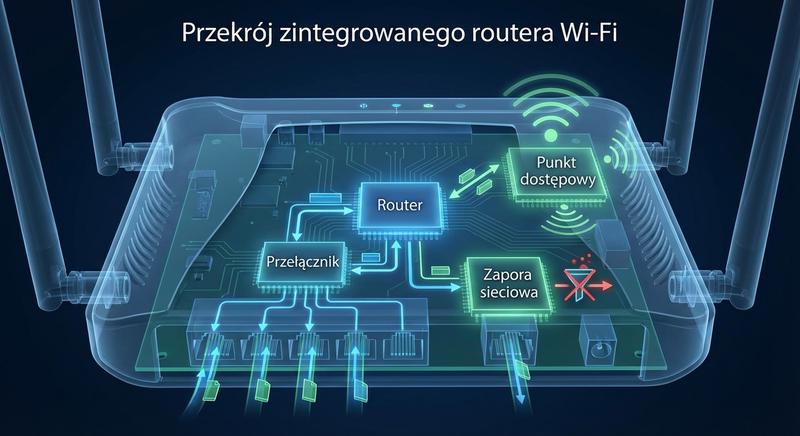
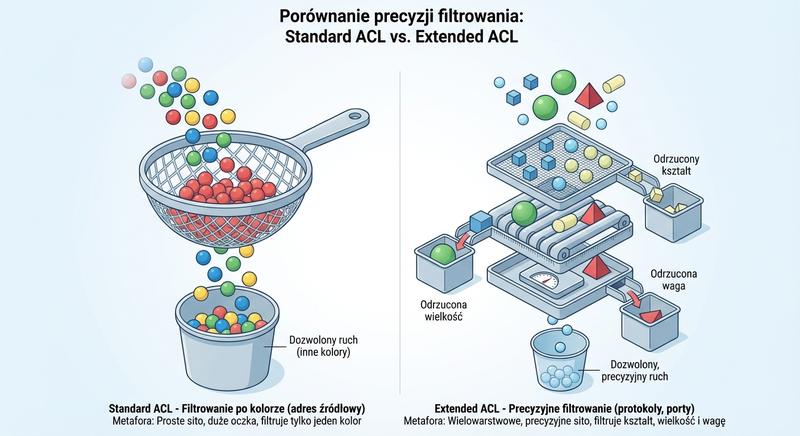
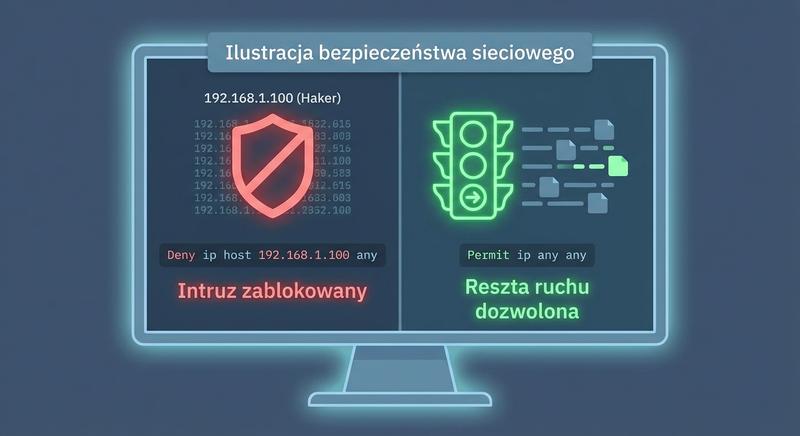
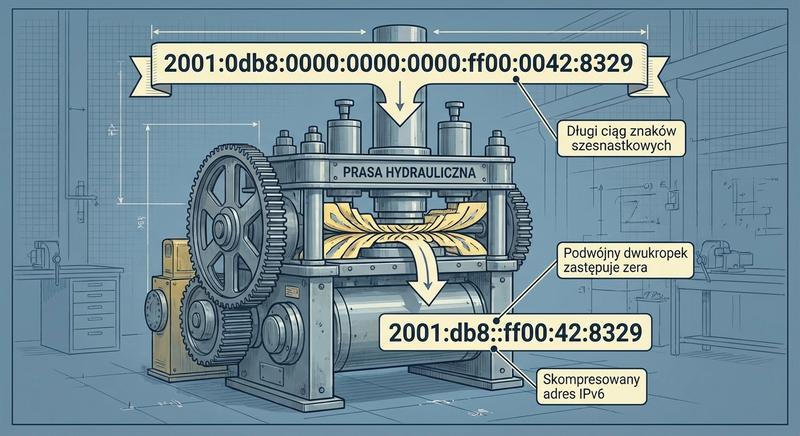
Witam na czwartym wykładzie!
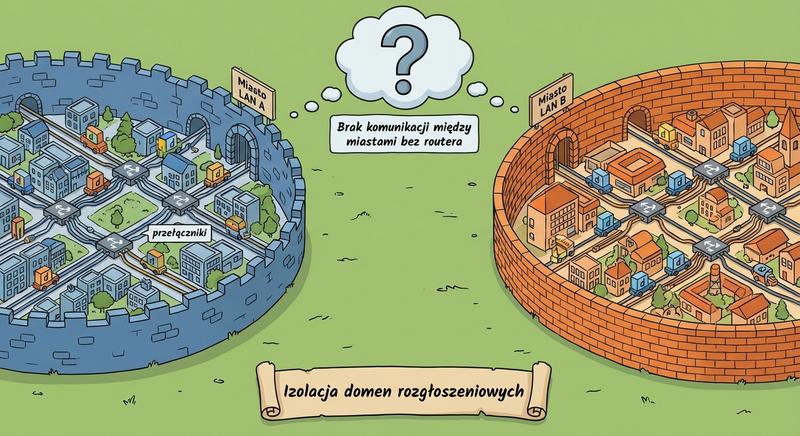
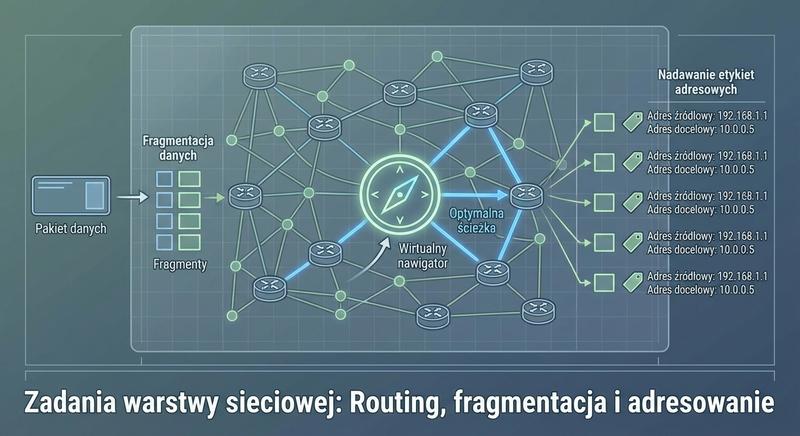
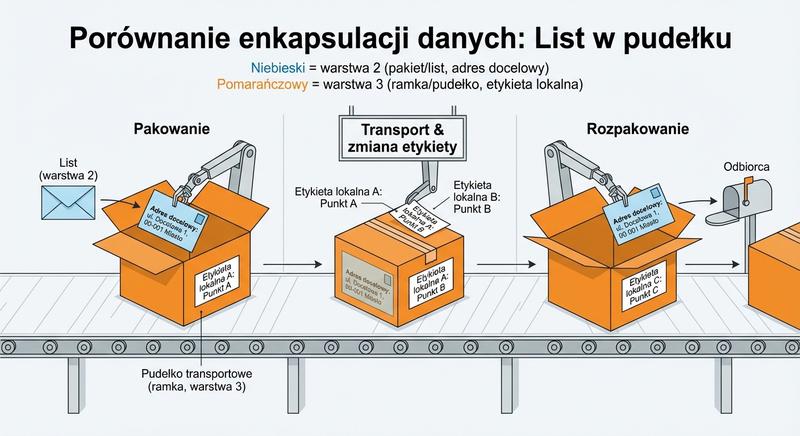
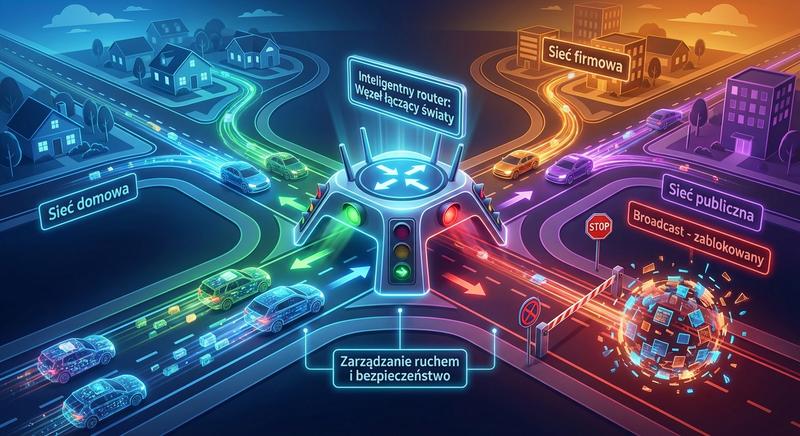
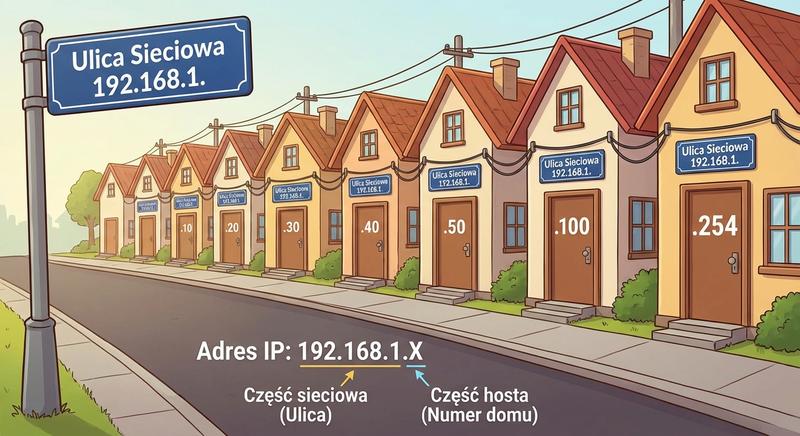
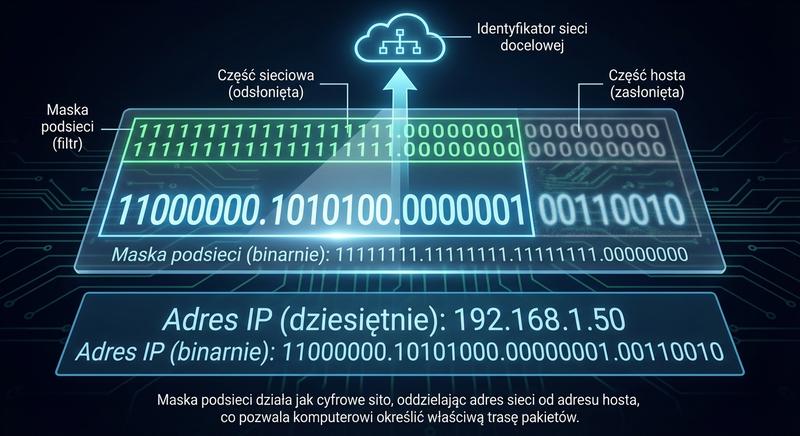
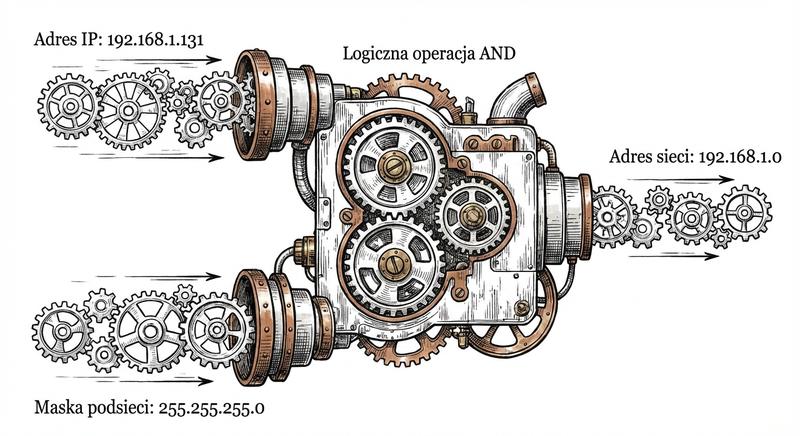
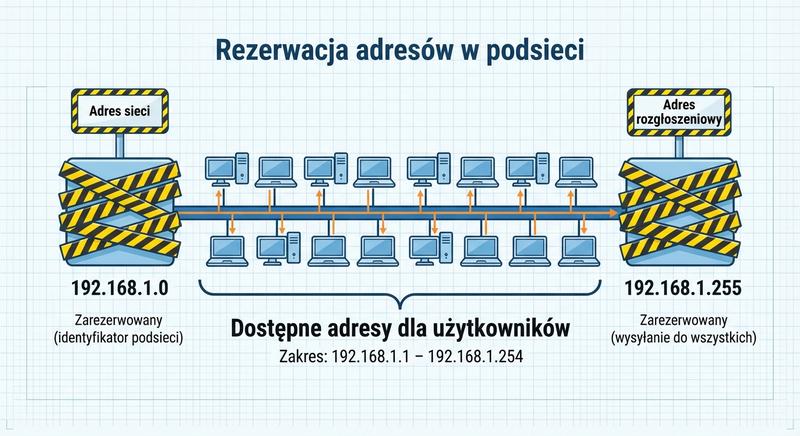
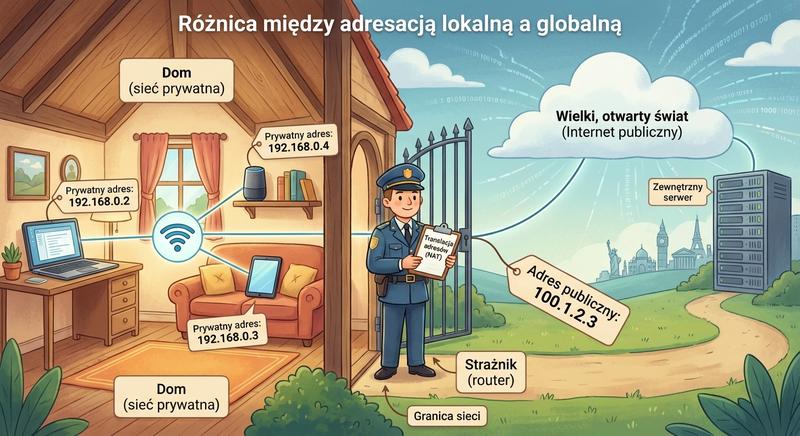
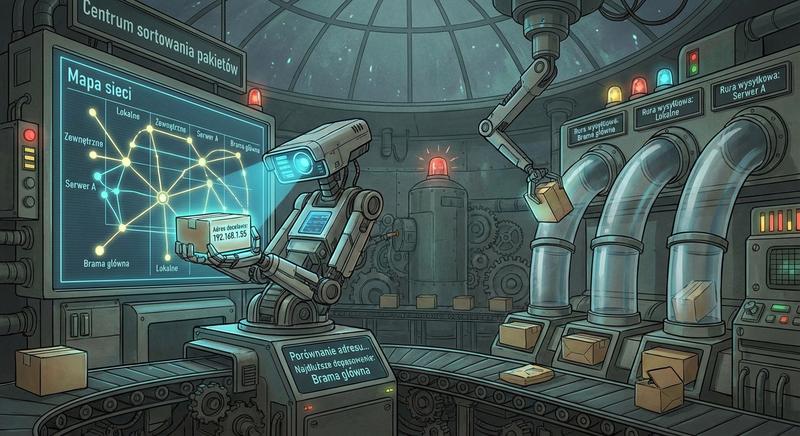
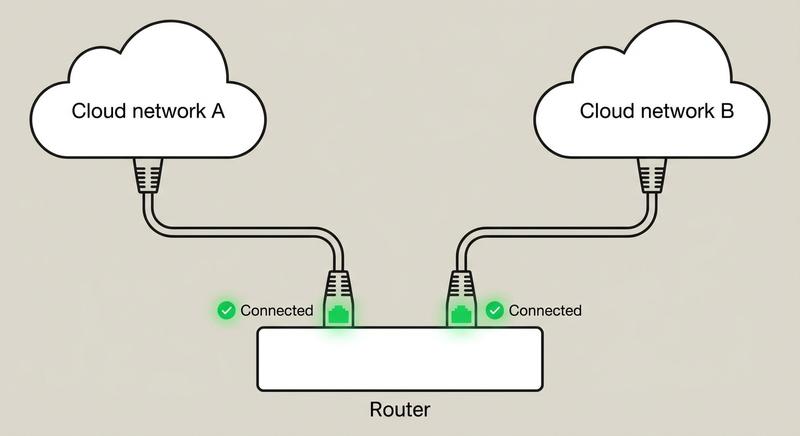
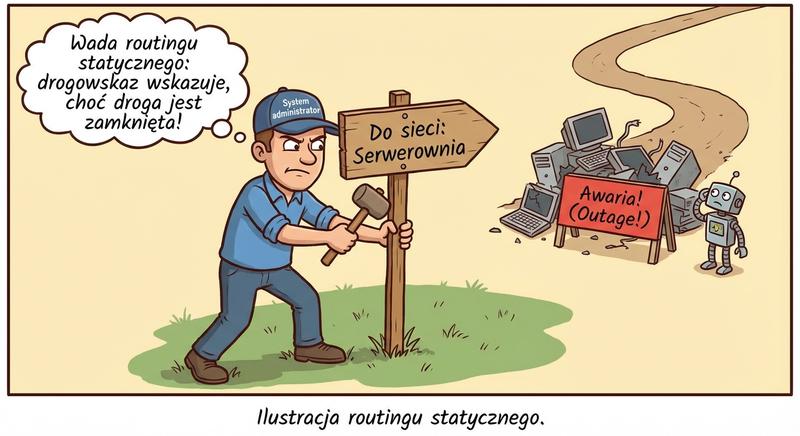
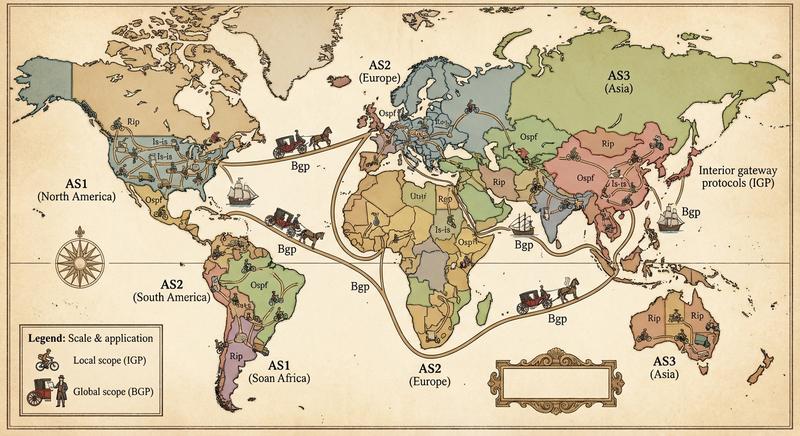
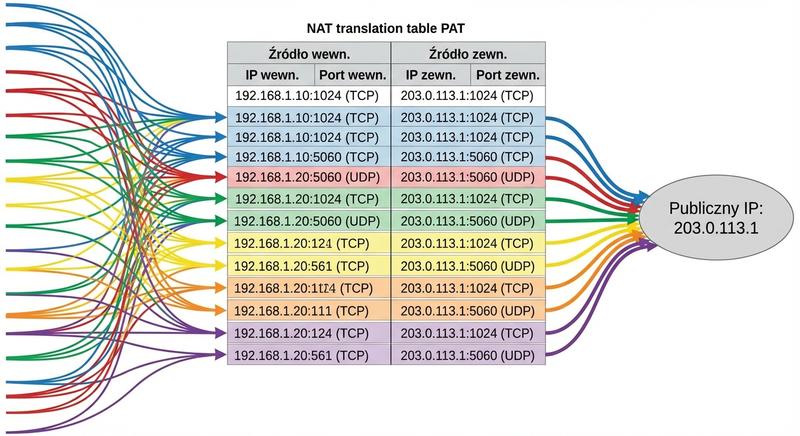
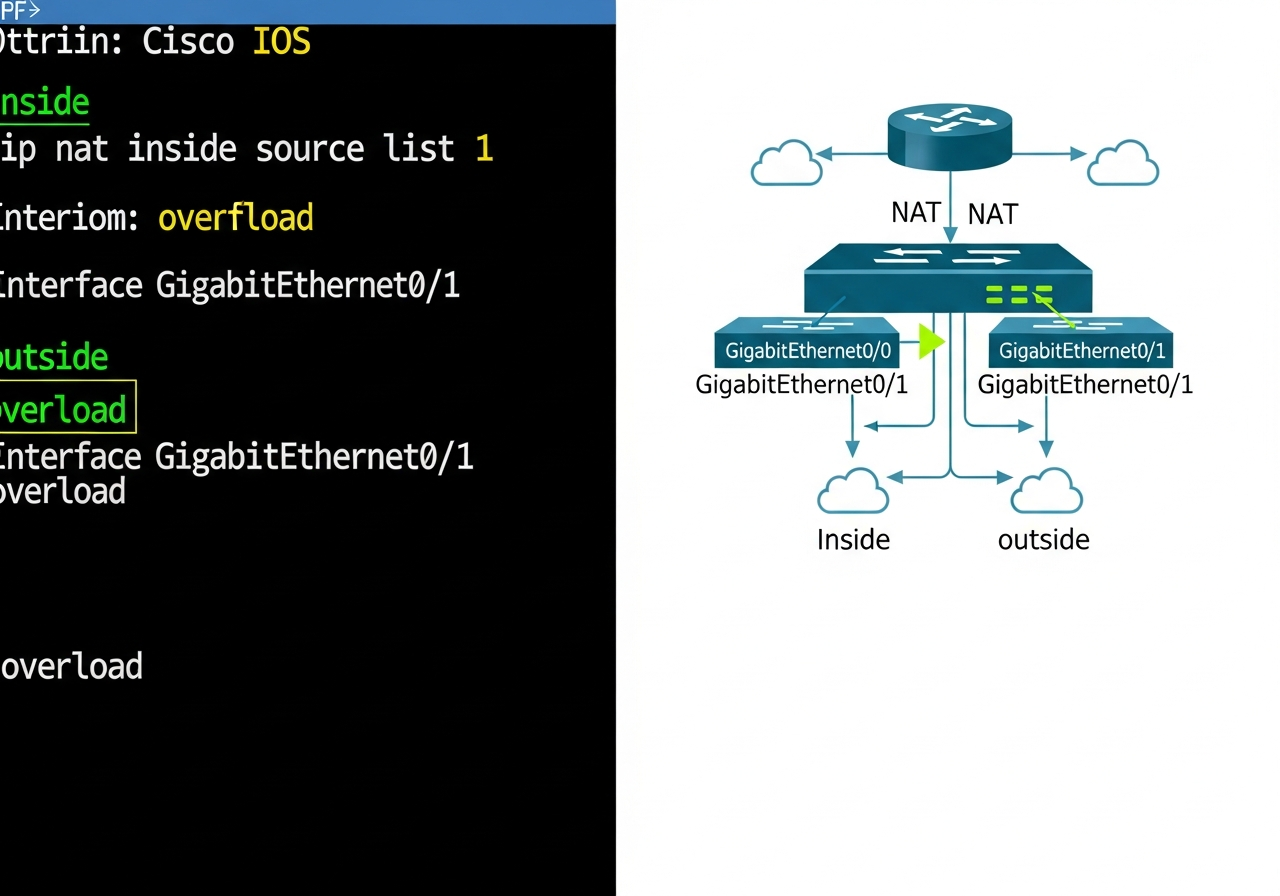
W poprzednich częściach poznaliśmy warstwy 1 i 2 modelu ISO/OSI – fizyczną transmisję bitów oraz adresację MAC umożliwiającą komunikację w obrębie lokalnej sieci LAN. Dziś wkraczamy w kluczowy obszar sieci komputerowych: warstwę sieciową, czyli warstwę 3. To właśnie tutaj odbywa się routing, czyli proces wyznaczania drogi dla pakietów danych pomiędzy odległymi sieciami, które mogą znajdować się na różnych kontynentach. Poznamy adresy IP, maski podsieci, routery i protokoły routingu – fundament działania globalnego Internetu.