Witam na trzecim wykładzie!
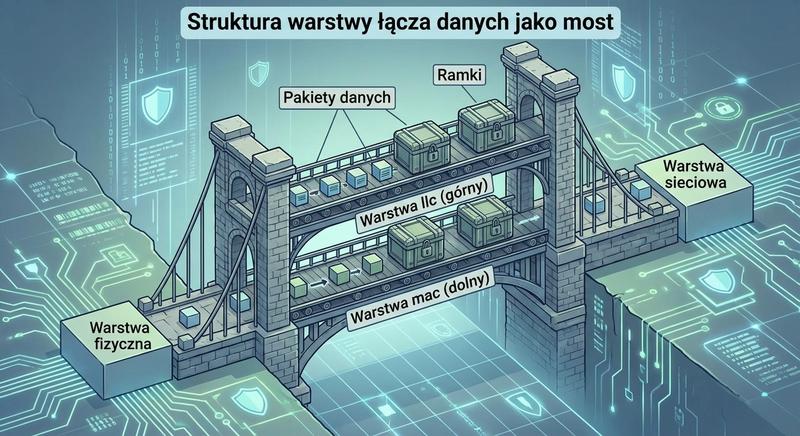
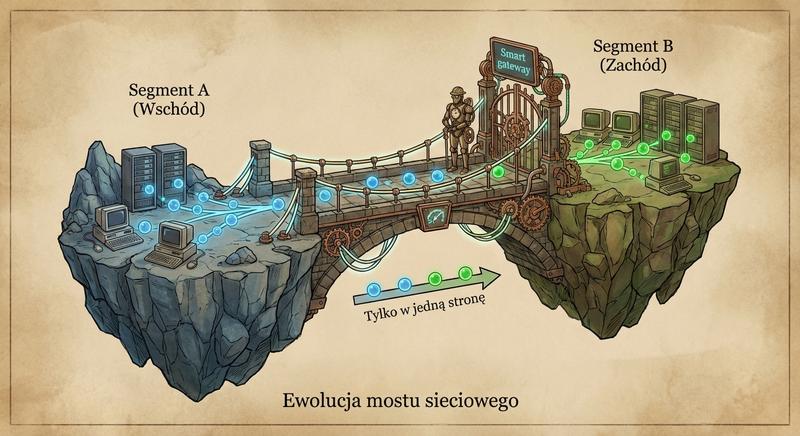
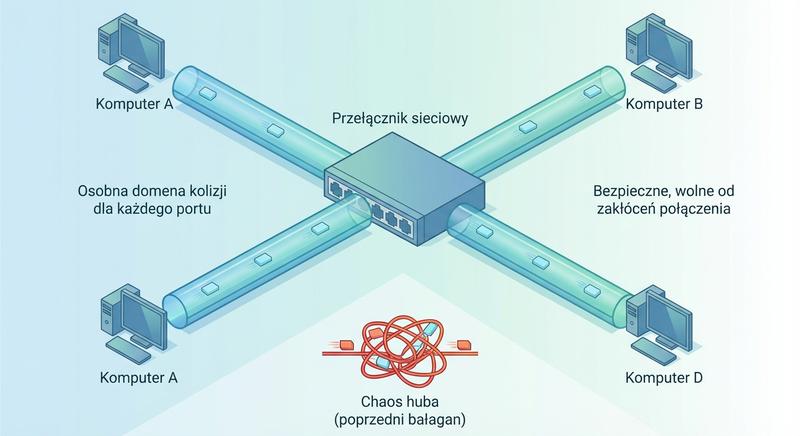
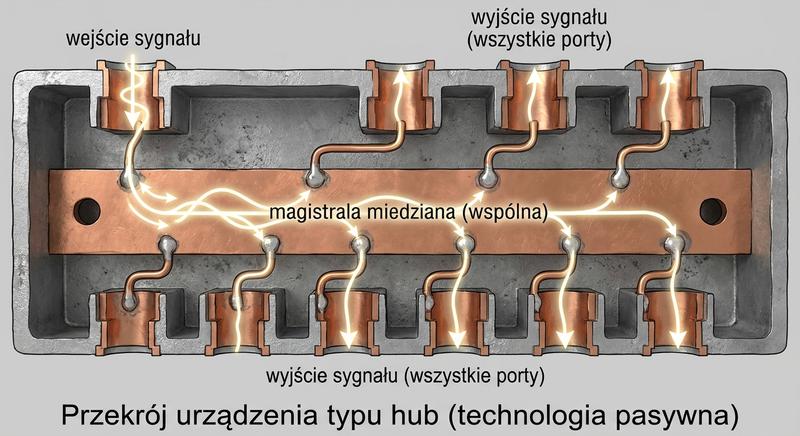
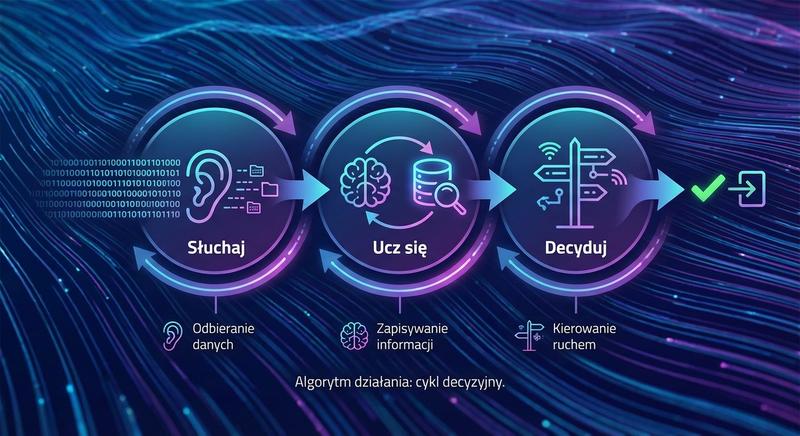
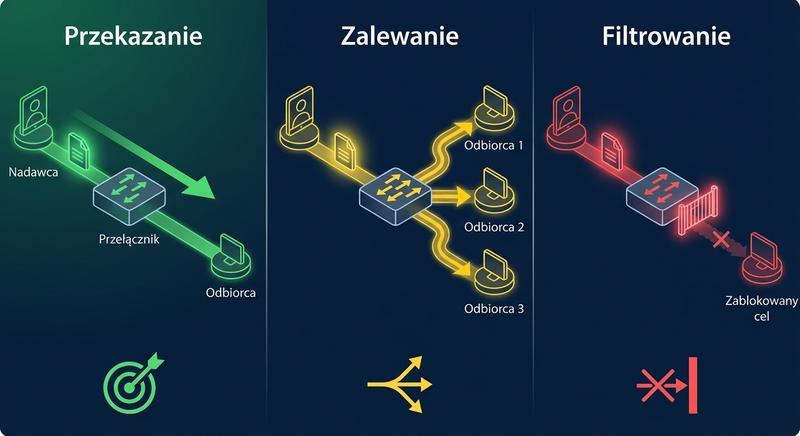
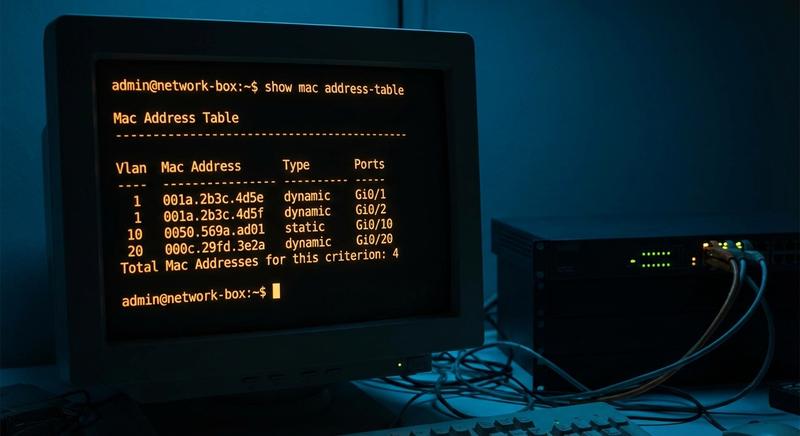
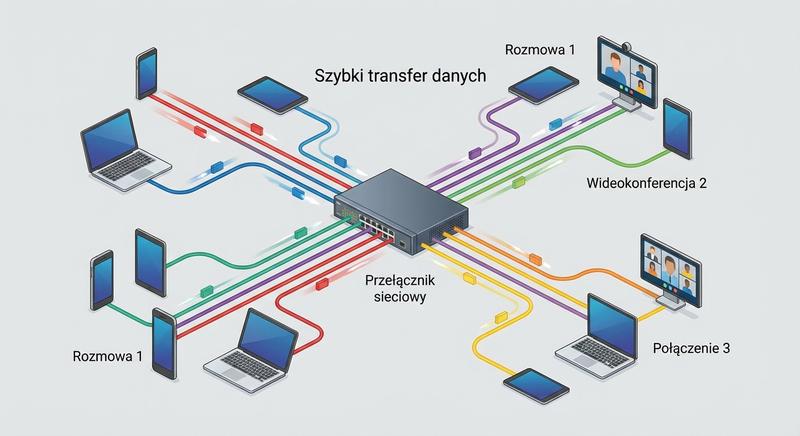
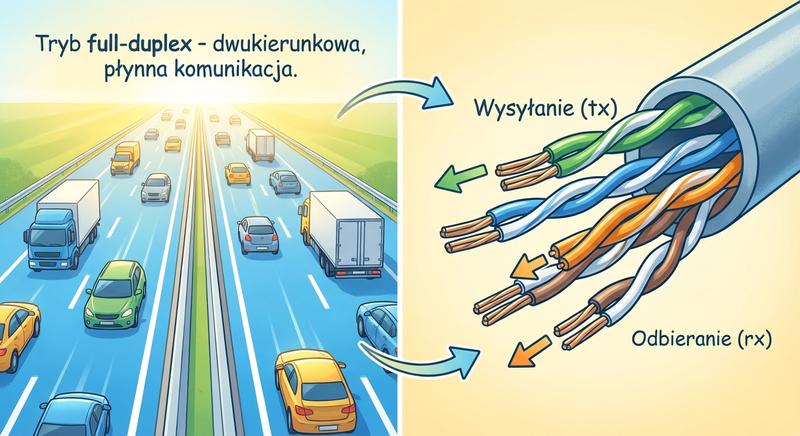
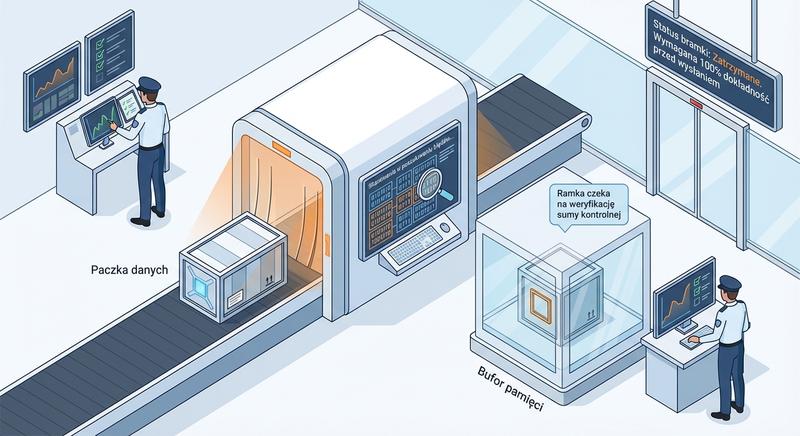
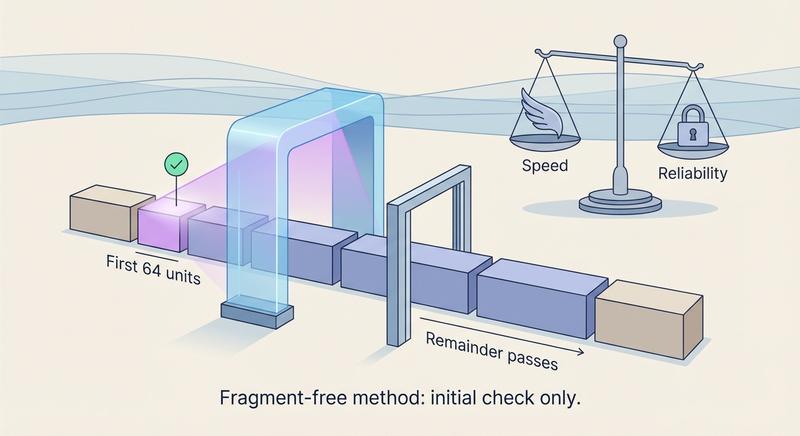
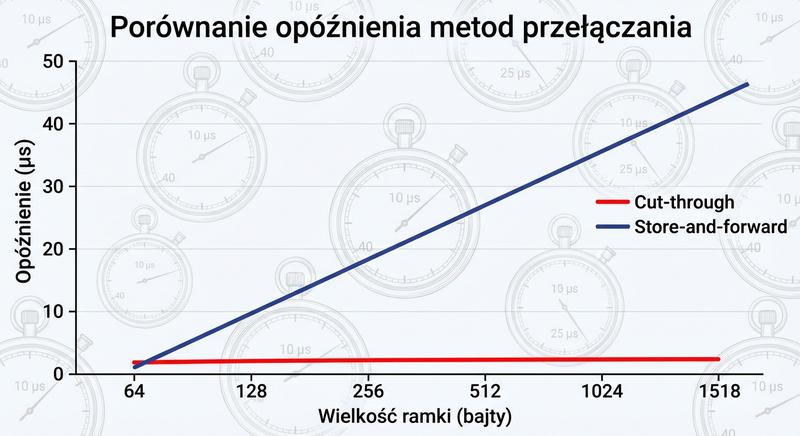
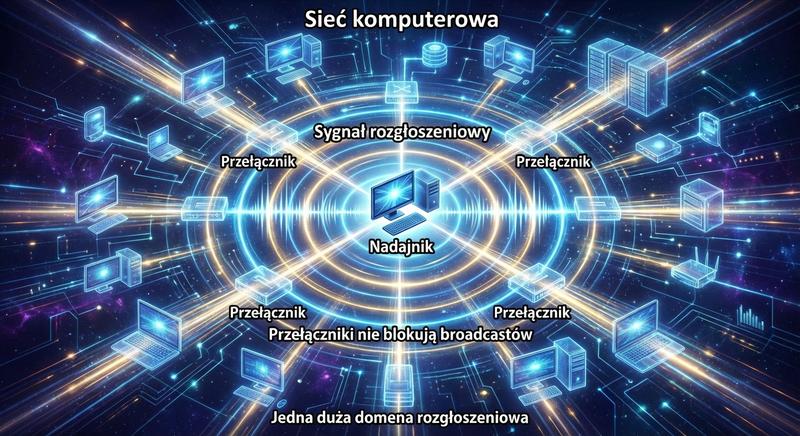
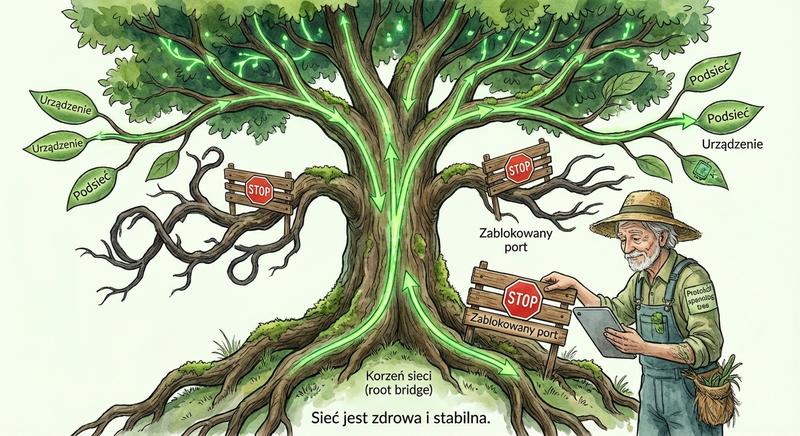
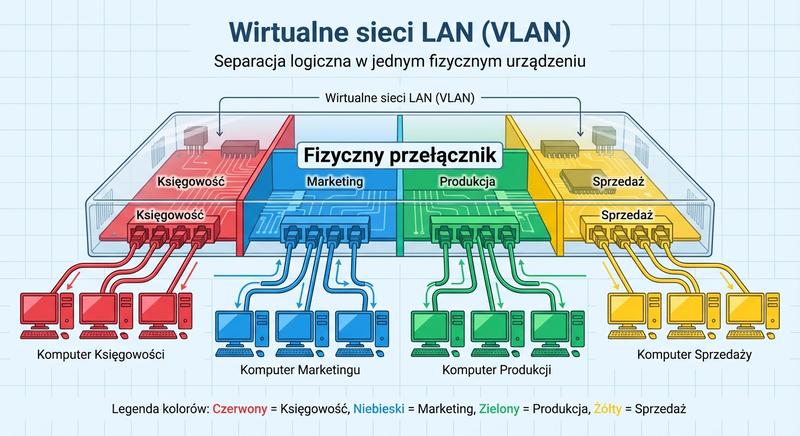
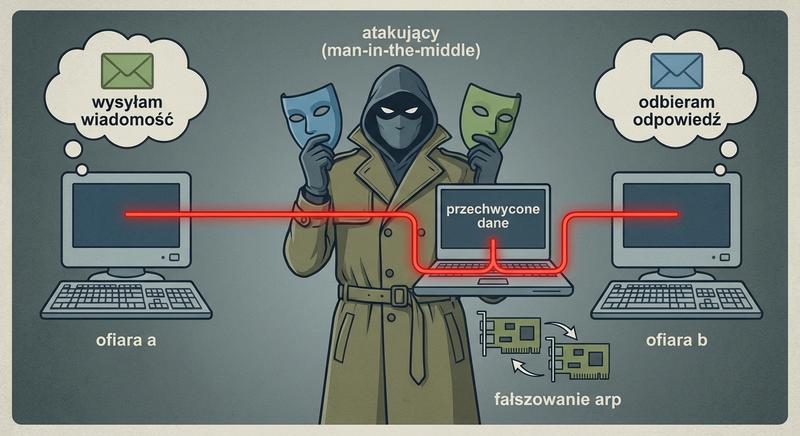
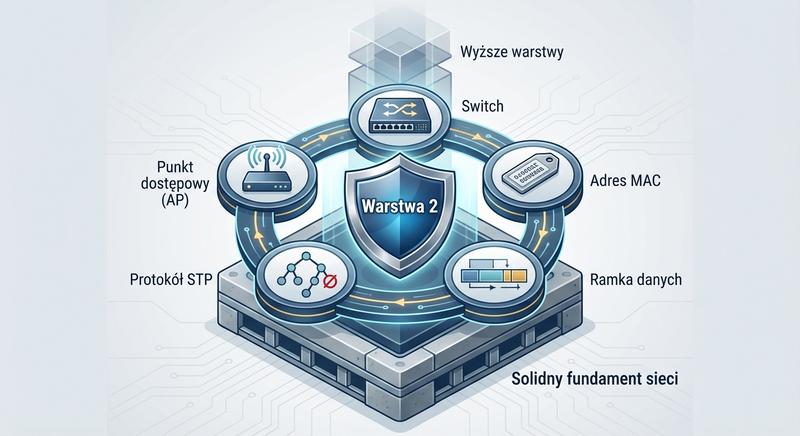
Witam Państwa na trzecim wykładzie z budowy i konfiguracji urządzeń sieciowych. Dziś wkraczamy w kluczową warstwę modelu ISO/OSI – warstwę łącza danych, zwaną również warstwą 2. Na poprzednich spotkaniach poznaliśmy podstawy Ethernetu oraz urządzenia warstwy fizycznej. Dzisiaj zajmiemy się urządzeniami, które potrafią analizować ramki, podejmować decyzje na podstawie adresów MAC i efektywnie zarządzać ruchem w sieci lokalnej. To właśnie te urządzenia – przede wszystkim przełączniki – stanowią kręgosłup współczesnych sieci LAN.