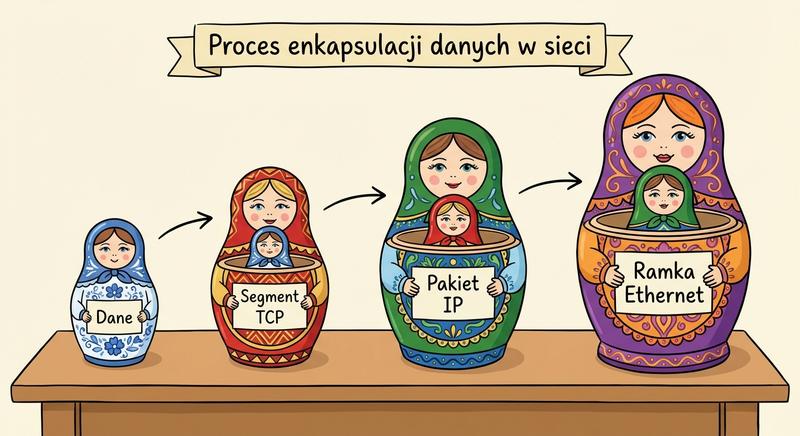
Witamy na ostatnim wykładzie!
W piątej, ostatniej części naszego kursu zajmiemy się urządzeniami działającymi w wyższych warstwach modelu OSI/TCP/IP. Omówimy firewalle, serwery proxy, load balancery, systemy IDS/IPS i wiele innych. Przyjrzymy się również urządzeniom wielowarstwowym oraz przyszłości sieci w kontekście programowalności i wirtualizacji. Zapraszam do ostatniej podróży przez świat infrastruktury sieciowej.
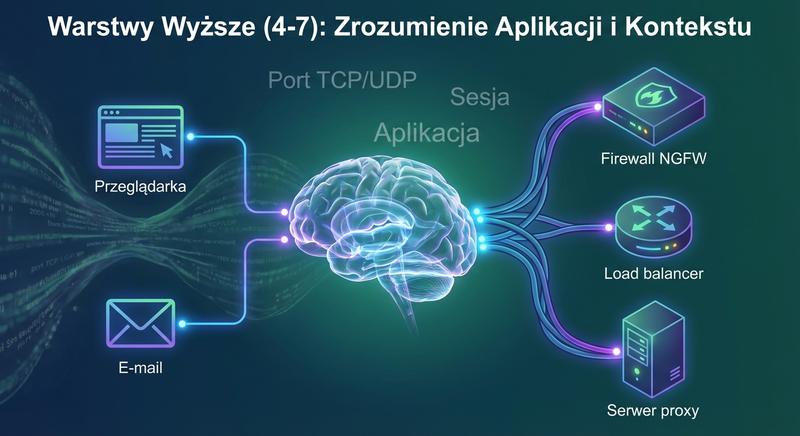
Warstwy wyższe modelu OSI, czyli warstwy od czwartej do siódmej, umożliwiają komunikację między aplikacjami działającymi na różnych hostach w sieci. Urządzenia wielowarstwowe łączą w sobie funkcje przełączania, rutowania oraz zaawansowanego przetwarzania danych na poziomie aplikacji. Zapory sieciowe nowej generacji potrafią analizować ruch nie tylko na podstawie adresów IP i portów, ale także treści przesyłanych pakietów. Serwery proxy działają jako pośrednicy między klientem a serwerem, oferując buforowanie i filtrowanie zawartości. Mechanizmy równoważenia obciążenia rozdzielają ruch między wiele serwerów, zwiększając wydajność i niezawodność usług. Systemy wykrywania i zapobiegania włamaniom monitorują sieć w poszukiwaniu podejrzanych wzorców i reagują w czasie rzeczywistym.
Wirtualizacja urządzeń sieciowych pozwala na uruchomienie wielu niezależnych instancji zapór, routerów czy przełączników na jednym fizycznym sprzęcie. Nowoczesne środowiska chmurowe w dużym stopniu opierają się na wirtualnych urządzeniach sieciowych, które można dynamicznie skalować. Urządzenia wielowarstwowe przyspieszają działanie sieci, ponieważ przejmują zadania, które wcześniej wymagały oddzielnych specjalistycznych urządzeń. Zrozumienie działania poszczególnych warstw jest kluczowe dla projektowania bezpiecznych i wydajnych sieci komputerowych. W dalszej części wykładu omówione zostaną konkretne typy urządzeń, ich budowa oraz praktyczne zastosowania.
Urządzenia warstw 1-3 (huby, switche, routery) zajmują się dostarczaniem danych między hostami. Wyższe warstwy umożliwiają aplikacjom efektywne korzystanie z tej infrastruktury.
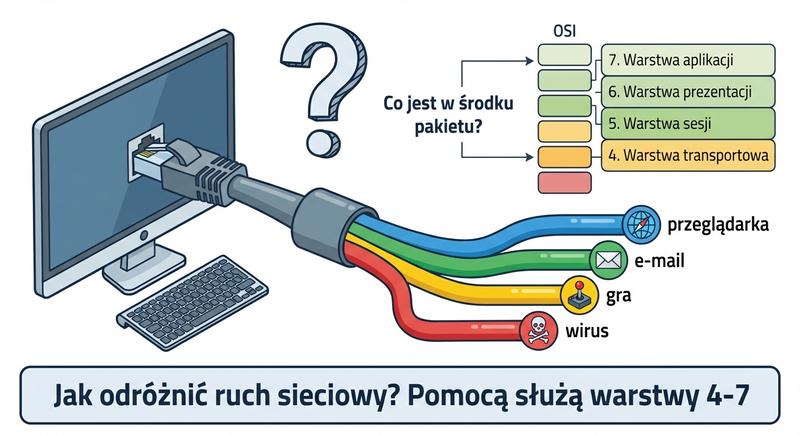
- Warstwa transportowa (L4): Odpowiada za niezawodność, kontrolę przepływu i multipleksowanie połączeń między aplikacjami.
- Warstwa sesji (L5): Zarządza nawiązywaniem, utrzymywaniem i zakończeniem sesji komunikacyjnych.
- Warstwa prezentacji (L6): Zajmuje się szyfrowaniem, kompresją i konwersją formatów danych.
- Warstwa aplikacji (L7): Udostępnia protokoły, z których bezpośrednio korzystają programy użytkownika (HTTP, DNS, SMTP).
Urządzenia działające w niższych warstwach modelu OSI, takie jak koncentratory, przełączniki i rutery, odpowiadają za dostarczanie danych między hostami, jednak nie mają świadomości rodzaju przesyłanego ruchu ani potrzeb aplikacji. Warstwy wyższe wprowadzają mechanizmy umożliwiające niezawodną komunikację między programami użytkowymi działającymi na różnych maszynach. Warstwa transportowa zapewnia niezawodność transmisji poprzez potwierdzenia i retransmisję zagubionych segmentów, a także kontroluje przepływ danych między nadawcą a odbiorcą. Multipletowanie strumieni danych za pomocą numerów portów pozwala wielu aplikacjom na jednoczesne korzystanie z jednego połączenia sieciowego. Bez tych mechanizmów przeglądanie stron internetowych, wysyłanie poczty czy przesyłanie plików byłoby niemożliwe lub wyjątkowo zawodne.
Warstwa sesji zarządza nawiązywaniem, utrzymywaniem i zrywaniem połączeń między aplikacjami, synchronizując wymianę danych. Warstwa prezentacji odpowiada za przekształcanie danych do formatu zrozumiałego dla aplikacji, w tym za szyfrowanie, kompresję i kodowanie znaków. Bez warstw wyższych rutery i przełączniki działałyby wyłącznie na podstawie adresów MAC i IP, bez możliwości podejmowania decyzji opartych na treści transmisji. Rozdzielenie funkcji na poszczególne warstwy modelu OSI umożliwia niezależny rozwój technologii na każdym poziomie abstrakcji.
Warstwa transportowa jest sercem komunikacji między aplikacjami. Działa jako pomost między warstwą sieciową a aplikacyjną, wprowadzając pojęcie portów i sesji.
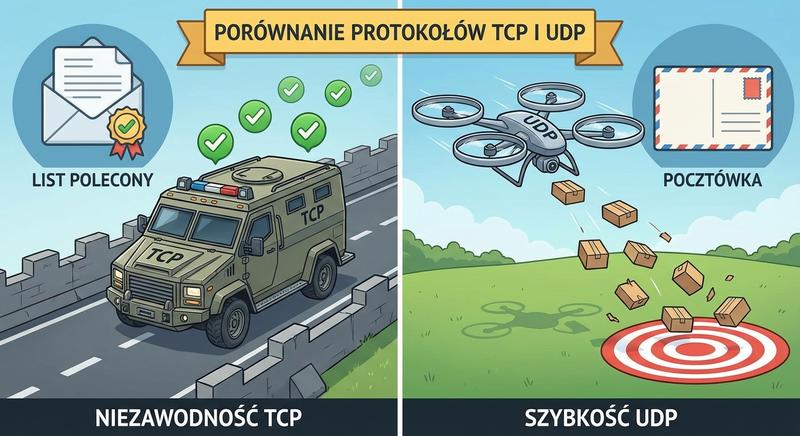
- TCP (Transmission Control Protocol): Protokół niezawodny, gwarantujący dostarczenie danych w odpowiedniej kolejności (połączeniowy). Stosowany tam, gdzie niezawodność jest kluczowa.
- UDP (User Datagram Protocol): Protokół zawodny, lekki i szybki (bezpołączeniowy). Idealny dla aplikacji czasu rzeczywistego, gdzie szybkość ma priorytet nad gwarancją dostarczenia.
- Multipleksowanie: Dzięki portom (źródłowym i docelowym) wiele aplikacji na jednym hoście może jednocześnie korzystać z sieci.
Warstwa transportowa stanowi serce komunikacji między aplikacjami, ponieważ to właśnie na tym poziomie odbywa się segmentacja danych i ich składanie po stronie odbiorcy. Protokół TCP gwarantuje dostarczenie danych w odpowiedniej kolejności, co jest niezbędne przy przesyłaniu plików, wiadomości e-mail czy stron internetowych. Protokół UDP rezygnuje z mechanizmów niezawodności na rzecz szybkości, co czyni go idealnym dla transmisji strumieniowych i gier sieciowych. Multipletowanie za pomocą portów źródłowych i docelowych umożliwia jednoczesną pracę wielu usług sieciowych na jednym hoście. Każda aplikacja sieciowa korzysta z określonego portu lub zakresu portów, co pozwala systemowi operacyjnemu na prawidłowe kierowanie pakietów do odpowiednich procesów.
Nagłówek TCP zawiera pola odpowiedzialne za numer sekwencyjny, potwierdzenie, okno sterowania przepływem oraz sumę kontrolną, co umożliwia wykrywanie i korygowanie błędów transmisji. Warstwa transportowa izoluje aplikacje od szczegółów działania sieci, dostarczając jednolity interfejs do wysyłania i odbierania danych. Protokół UDP jest często wykorzystywany w systemach czasu rzeczywistego, gdzie opóźnienia są bardziej szkodliwe niż sporadyczna utrata pakietów. Znajomość mechanizmów warstwy transportowej jest niezbędna przy konfigurowaniu zapór sieciowych i reguł filtrowania ruchu.
Wybór między TCP a UDP ma kluczowe znaczenie dla każdej aplikacji sieciowej. Każdy z tych protokołów został zaprojektowany z myślą o innych zastosowaniach.
- TCP: Nawiązuje trójfazowe uzgadnianie (three-way handshake – SYN, SYN-ACK, ACK), zapewnia retransmisję utraconych segmentów, kontrolę przepływu (okno przesuwne) i kontrolę przeciążeń.
- UDP: Nie nawiązuje połączenia – dane są wysyłane natychmiast (fire-and-forget). Brak retransmisji, kolejkowania czy kontroli przepływu.
- TCP używa się w przeglądarkach (HTTP/HTTPS), poczcie (SMTP, IMAP), transferze plików (FTP). UDP stosuje się w strumieniowaniu wideo, VoIP (RTP), grach online oraz w DNS i DHCP.
Protokół TCP przed rozpoczęciem właściwej transmisji wykonuje trójstopniowe uzgadnianie, w ramach którego klient i serwer wymieniają pakiety SYN, SYN-ACK i ACK w celu ustalenia parametrów połączenia. Działanie protokołu UDP opiera się na zasadzie "odeślij i zapomnij", gdzie nadawca nie otrzymuje żadnego potwierdzenia dostarczenia datagramu. TCP implementuje mechanizm okna przesuwnego, który dynamicznie dostosowuje ilość danych wysyłanych bez potwierdzenia do aktualnych warunków sieciowych. W przypadku przeciążenia sieci TCP zmniejsza szybkość transmisji, podczas gdy UDP kontynuuje wysyłanie z tą samą prędkością. Aplikacje wymagające wysokiej przepustowości i tolerujące straty pakietów, takie jak transmisja wideo na żywo, świadomie wybierają UDP jako protokół transportowy.
Poczta elektroniczna wykorzystuje TCP do dostarczania wiadomości za pośrednictwem protokołów SMTP, POP3 i IMAP, gdzie niezawodność jest kluczowa. System DNS stosuje UDP dla zapytań podstawowych ze względu na mały rozmiar pakietów i konieczność szybkiej odpowiedzi, natomiast w przypadku transferów stref przełącza się na TCP. Protokół HTTP i jego szyfrowana wersja HTTPS działają wyłącznie na TCP, ponieważ przeglądarki wymagają pewności, że strona załadowała się w całości. Streaming wideo i protokoły komunikacji głosowej, takie jak RTP, opierają się na UDP, aby uniknąć opóźnień spowodowanych retransmisją zagubionych pakietów.
Warstwa aplikacji to najwyższa warstwa modeli OSI i TCP/IP. Choć w modelu OSI jest to warstwa 7, w praktyce to ona jest najlepiej widoczna dla użytkownika – to właśnie z jej protokołami obcujemy na co dzień.
Do najważniejszych protokołów warstwy aplikacji należą: HTTP/HTTPS (strony WWW), DNS (tłumaczenie nazw na adresy IP), SMTP/POP3/IMAP (poczta elektroniczna), FTP/SFTP (transfer plików), SSH (zdalny dostęp), DHCP (automatyczna konfiguracja sieci) oraz protokoły strumieniowania multimediów. Zrozumienie tych protokołów jest niezbędne do konfiguracji zaawansowanych urządzeń, takich jak firewalle aplikacyjne czy load balancery L7.
Warstwa aplikacji w modelu OSI stanowi interfejs między siecią a programami użytkowymi, udostępniając protokoły umożliwiające wymianę danych na poziomie użytkownika. Protokół HTTP jest podstawą działania sieci WWW, definiując sposób formatowania i przesyłania zapytań oraz odpowiedzi między przeglądarką a serwerem. DNS pełni kluczową rolę w tłumaczeniu nazw domenowych na adresy IP, bez których korzystanie z internetu nie byłoby tak wygodne. Protokoły pocztowe SMTP, POP3 i IMAP umożliwiają wysyłanie i odbieranie wiadomości e-mail, każdy z nich służy do innych zadań. SSH zapewnia bezpieczny zdalny dostęp do systemów, szyfrując cały kanał komunikacyjny.
Protokół DHCP automatyzuje konfigurację sieciową urządzeń, przydzielając adresy IP, maski podsieci i bramy domyślne bez ingerencji administratora. Protokoły strumieniowania, takie jak RTMP i HLS, działają w warstwie aplikacji i umożliwiają dostarczanie treści multimedialnych w czasie rzeczywistym. Wiele nowoczesnych urządzeń sieciowych, zwłaszcza zapory nowej generacji, potrafi analizować ruch właśnie na poziomie warstwy aplikacji. Zrozumienie protokołów warstwy aplikacji jest niezbędne do skutecznego konfigurowania polityk bezpieczeństwa i optymalizacji działania sieci. Każdy z tych protokołów korzysta z określonych portów warstwy transportowej, co pozwala na ich identyfikację i filtrowanie.
Firewall (zapora sieciowa) to fundamentalne urządzenie bezpieczeństwa, którego głównym zadaniem jest kontrola ruchu sieciowego na podstawie zdefiniowanego zestawu reguł. Działa jako bariera między zaufaną siecią wewnętrzną (LAN) a niezaufaną siecią zewnętrzną (np. Internet).
Firewalle mogą być urządzeniami dedykowanymi (sprzętowymi) lub programowymi działającymi na systemach operacyjnych. Współczesne firewalle potrafią analizować ruch od warstwy 2 aż do warstwy 7 modelu OSI. Podstawową funkcją każdej zapory jest filtrowanie pakietów, ale różne typy zapór robią to z różnym stopniem zaawansowania.
Zapora sieciowa to urządzenie lub program służący do kontrolowania ruchu sieciowego na podstawie zdefiniowanych reguł bezpieczeństwa, stanowiący pierwszą linię obrony przed nieautoryzowanym dostępem. Zapory mogą działać jako sprzętowe urządzenia dedykowane lub jako oprogramowanie instalowane na serwerach i komputerach końcowych. W zależności od zaawansowania zapora może analizować pakiety od drugiej warstwy modelu OSI, czyli warstwy łącza danych, aż do siódmej warstwy aplikacji. Podstawowym zadaniem zapory jest przepuszczanie ruchu zgodnego z regułami i blokowanie wszystkiego, co tych reguł nie spełnia. Nowoczesne zapory potrafią identyfikować użytkowników, aplikacje i typy zawartości, a nie tylko adresy i porty.
Zapory sieciowe są kluczowym elementem każdej architektury bezpieczeństwa, zarówno w sieciach firmowych, jak i w domowych routerach. Reguły zapory definiuje się zazwyczaj na podstawie kierunku ruchu, źródłowego i docelowego adresu IP, protokołu oraz portu. W zaawansowanych konfiguracjach zapory mogą również sprawdzać stan połączenia oraz przeprowadzać głęboką inspekcję pakietów. Zapory programowe działające na urządzeniach końcowych stanowią uzupełnienie zapory sieciowej, tworząc ochronę wielowarstwową. Prawidłowe skonfigurowanie zapory wymaga znajomości protokołów sieciowych i architektury chronionej sieci.
Najprostsza forma zapory to filtr bezstanowy (stateless firewall) lub zwykły filtr pakietów. Analizuje on każdy pakiet w izolacji, bez pamiętania kontekstu wcześniejszych pakietów.
- Decyzje podejmowane na podstawie: adresu IP źródła i celu, portu TCP/UDP źródła i celu, protokołu (TCP, UDP, ICMP) oraz flag TCP (np. SYN, ACK).
- Zalety: Szybkość i prostota – filtr nie musi utrzymywać tablic stanów, co minimalizuje opóźnienia i zużycie pamięci.
- Wady: Nie rozumie kontekstu połączenia – każdy pakiet oceniany jest niezależnie. Umożliwia to ataki polegające na wstrzykiwaniu pakietów w istniejący strumień (np. blind TCP injection).
Filtracja bezstanowa, zwana również filtrowaniem pakietów, polega na analizie każdego pakietu z osobna bez uwzględniania kontekstu wcześniejszej komunikacji. Reguły filtracji bezstanowej opierają się na źródłowym i docelowym adresie IP, numerach portów protokołu transportowego oraz flagach TCP. To najprostsza i najszybsza metoda filtrowania, ponieważ zapora nie musi przechowywać informacji o stanie aktywnych połączeń. Ze względu na swoją prostotę zapory bezstanowe są podatne na ataki polegające na podszywaniu się pod zaufane adresy IP. Filtracja bezstanowa sprawdza się dobrze w prostych scenariuszach, gdzie wymagana jest wysoka wydajność przy niewielkim obciążeniu administracyjnym.
W zapórze bezstanowej każdy pakiet jest oceniany wyłącznie na podstawie własnego nagłówka, bez możliwości powiązania go z wcześniejszymi pakietami tej samej sesji. Oznacza to, że aby przepuścić ruch odpowiedzi, administrator musi ręcznie dodać reguły zezwalające na ruch powrotny. Zapory bezstanowe nie potrafią odróżnić prawidłowego pakietu odpowiedzi od celowo spreparowanego pakietu z fałszywym adresem źródłowym. Mimo swoich ograniczeń zapory bezstanowe są wciąż używane w środowiskach, gdzie priorytetem jest przepustowość, a nie zaawansowane bezpieczeństwo. Nowoczesne implementacje często łączą filtrację bezstanową ze stanową w celu uzyskania optymalnej wydajności i bezpieczeństwa.
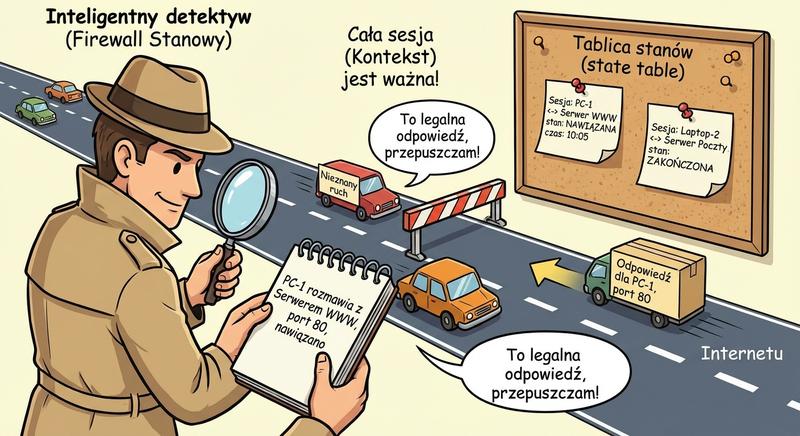
Kluczowym udoskonaleniem w stosunku do filtrów bezstanowych jest zapora stanowa (stateful firewall). To właśnie ten typ urządzenia przez lata był standardem w ochronie sieci korporacyjnych.
Zapora stanowa utrzymuje tablicę stanów (state table), w której rejestruje wszystkie aktywne połączenia przechodzące przez nią. Kiedy pakiet SYN inicjuje nowe połączenie TCP, zapora tworzy wpis w tabeli. Kolejne pakiety w ramach tego samego połączenia są porównywane z wpisem – jeśli pasują do stanu „ustanowione", są przepuszczane automatycznie, bez ponownej analizy reguł. Po zakończeniu połączenia (FIN lub RST) wpis jest usuwany. Dzięki temu zapora skutecznie blokuje pakiety, które nie należą do żadnej zainicjowanej sesji.
Zapora stanowa przechowuje tablicę stanów połączeń, w której rejestrowane są wszystkie aktywne sesje sieciowe przebiegające przez urządzenie. Gdy pakiet SYN inicjuje nowe połączenie TCP, zapora tworzy wpis w tablicy stanu i oznacza go jako nienawiązane połączenie. Kolejne pakiety należące do tego samego strumienia są porównywane z wpisem w tablicy, co pozwala na szybkie podejmowanie decyzji o przepuszczeniu lub odrzuceniu. Po otrzymaniu pakietów FIN lub RST zapora usuwa odpowiedni wpis z tablicy, zwalniając zasoby pamięci. Dzięki mechanizmowi stanowemu zapora może automatycznie przepuszczać pakiety odpowiedzi bez konieczności ręcznego definiowania reguł dla ruchu powrotnego.
Zapora stanowa analizuje nie tylko nagłówki poszczególnych pakietów, ale również sekwencję i zgodność numerów sekwencyjnych TCP w ramach danego połączenia. Dzięki temu potrafi wykryć próby ataków polegających na wstrzyknięciu fałszywych pakietów do istniejącej sesji. Tablica stanów połączeń jest przechowywana w pamięci podręcznej zapory, co pozwala na błyskawiczne podejmowanie decyzji dla kolejnych pakietów. Zapory stanowe są standardem w nowoczesnych sieciach korporacyjnych, ponieważ łączą wysokie bezpieczeństwo z akceptowalną wydajnością. Wdrożenie zapory stanowej znacząco podnosi poziom bezpieczeństwa sieci w porównaniu z filtracją bezstanową.
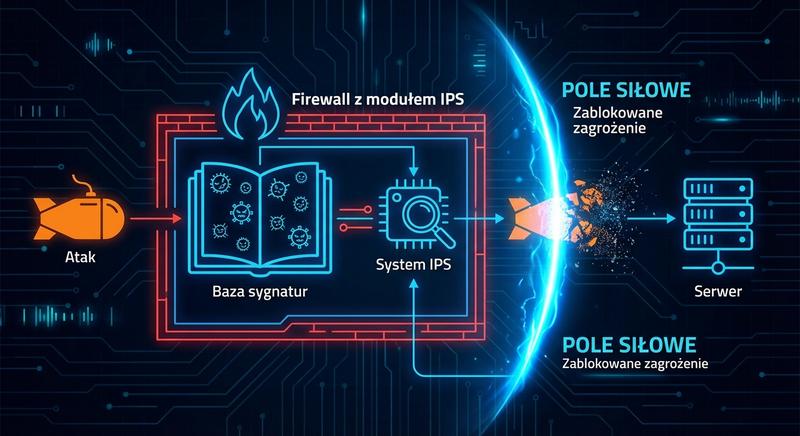
Firewalle nowej generacji (NGFW – Next-Generation Firewall) to odpowiedź na ewolucję zagrożeń i rosnącą złożoność ruchu sieciowego. Tradycyjna inspekcja stanowa nie wystarcza, gdy aplikacje maskują się na innych portach (np. komunikatory na porcie 80) lub gdy w ruchu HTTPS ukryte jest złośliwe oprogramowanie.
NGFW łączy w sobie funkcje klasycznej zapory stanowej z dodatkowymi mechanizmami bezpieczeństwa, takimi jak głęboka inspekcja pakietów (DPI), system zapobiegania włamaniom (IPS), kontrola aplikacji niezależna od portów oraz często odszyfrowywanie i analiza ruchu TLS/SSL. Przykładami takich urządzeń są Palo Alto Networks, Fortinet FortiGate, Check Point czy Cisco Firepower.
Zapora nowej generacji, w skrócie NGFW, łączy w sobie możliwości tradycyjnej zapory stanowej z zaawansowanymi funkcjami analizy ruchu na poziomie aplikacji. Urządzenia NGFW potrafią przeprowadzać głęboką inspekcję pakietów, analizując nie tylko nagłówki, ale również treść przesyłanych danych. Wbudowany system zapobiegania włamaniom pozwala na wykrywanie i blokowanie ataków w czasie rzeczywistym bez potrzeby stosowania oddzielnych urządzeń. Kontrola aplikacji umożliwia identyfikację konkretnych programów i usług sieciowych niezależnie od używanego portu czy protokołu. Zapory nowej generacji potrafią również odszyfrowywać ruch TLS i SSL w celu inspekcji szyfrowanych transmisji.
Do najpopularniejszych producentów zapór nowej generacji należą Palo Alto Networks, Fortinet, Check Point oraz Cisco z serią Firepower. Urządzenia NGFW często wykorzystują dedykowane układy ASIC lub FPGA do przyspieszenia operacji związanych z głęboką inspekcją pakietów. Wdrożenie zapory nowej generacji pozwala na zastąpienie kilku oddzielnych urządzeń jednym, co upraszcza architekturę sieci i obniża koszty utrzymania. Polityki bezpieczeństwa w NGFW można definiować na podstawie tożsamości użytkownika, grupy, aplikacji i zawartości, a nie tylko adresów IP. Elastyczność konfiguracji sprawia, że zapory nowej generacji sprawdzają się zarówno w małych firmach, jak i w dużych centrach danych.
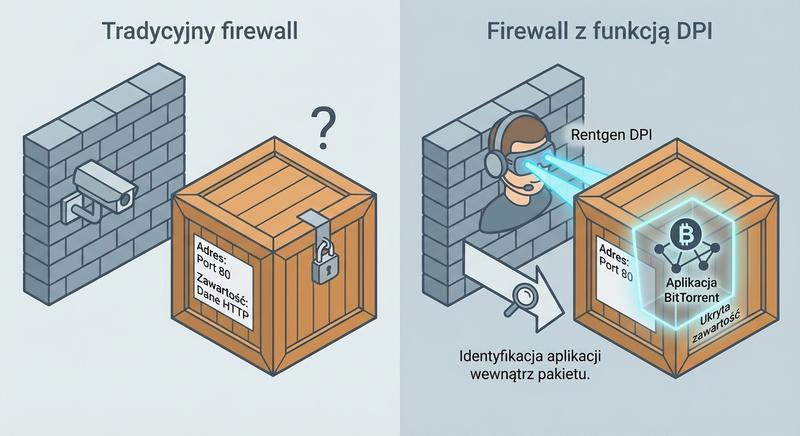
Deep Packet Inspection (DPI) to technologia pozwalająca na analizę nie tylko nagłówków pakietów, ale również ich zawartości (payload) – czyli właściwych danych przesyłanych przez aplikacje. DPI sięga głęboko w strukturę pakietu, aż do warstwy aplikacji.
Dzięki DPI firewall jest w stanie identyfikować konkretne protokoły i aplikacje niezależnie od używanego portu (np. wykryć ruch BitTorrent na porcie 80), wykrywać sygnatury złośliwego oprogramowania (pattern matching), blokować określone treści (filtrowanie URL, słowa kluczowe) oraz identyfikować typy plików przesyłane w ruchu sieciowym. DPI wymaga znacznych zasobów obliczeniowych i często jest wspomagane przez dedykowane układy ASIC lub FPGA.
Głęboka inspekcja pakietów polega na szczegółowej analizie całej zawartości pakietu sieciowego, a nie tylko jego nagłówków, co pozwala na wykrywanie zagrożeń ukrytych w przesyłanych danych. Mechanizm DPI porównuje treść pakietów z bazą sygnatur znanych ataków, złośliwego oprogramowania oraz wzorców charakterystycznych dla konkretnych protokołów. Dzięki inspekcji warstwy aplikacji zapora może identyfikować protokoły nawet wtedy, gdy używają niestandardowych portów w celu ominięcia prostych reguł filtracji. Głęboka inspekcja pakietów wymaga znacznych zasobów obliczeniowych, dlatego nowoczesne zapory wykorzystują do tego zadania wyspecjalizowane układy sprzętowe. Inspekcja DPI jest niezbędna do skutecznej kontroli aplikacji i wykrywania zaawansowanych zagrożeń, które nie są widoczne na poziomie nagłówków.
Układy ASIC i FPGA stosowane w zaawansowanych zaporach pozwalają na przetwarzanie milionów pakietów na sekundę przy jednoczesnym zachowaniu niskiego opóźnienia. Głęboka inspekcja pakietów umożliwia również blokowanie określonych typów plików, słów kluczowych lub wzorców danych w transmisji. DPI jest szczególnie skuteczne w wykrywaniu ruchu związanego z botnetami, ponieważ potrafi zidentyfikować charakterystyczne wzorce komunikacji z serwerami dowodzenia. W przypadku ruchu szyfrowanego zapora musi najpierw odszyfrować połączenie, aby móc przeprowadzić głęboką inspekcję jego zawartości. Wdrożenie DPI wymaga starannego dostrojenia reguł, aby uniknąć fałszywych alarmów i nadmiernego obciążenia urządzenia.
Intrusion Prevention System (IPS) to mechanizm aktywnej ochrony sieci, który monitoruje ruch w czasie rzeczywistym i automatycznie blokuje wykryte zagrożenia. IPS jest często zintegrowany z NGFW jako jeden z kluczowych modułów.
Działanie IPS opiera się na kilku metodach: analizie sygnatur (porównywanie wzorców ruchu z bazą znanych ataków), analizie anomalii (wykrywanie odchyleń od normalnego profilu ruchu), analizie protokołów (weryfikacja zgodności z RFC) oraz heurystyce i uczeniu maszynowym. W przeciwieństwie do IDS (Intrusion Detection System), który tylko alarmuje, IPS podejmuje natychmiastowe działania blokujące – np. resetuje połączenie TCP, blokuje adres IP źródła na określony czas lub dropuje pakiet.
System zapobiegania włamaniom wbudowany w zaporę nowej generacji monitoruje ruch sieciowy w czasie rzeczywistym i aktywnie blokuje wykryte zagrożenia. W przeciwieństwie do systemu wykrywania włamań, który jedynie powiadamia o zagrożeniu, IPS automatycznie odrzuca szkodliwe pakiety, zanim dotrą one do celu. Analiza sygnaturowa polega na porównywaniu ruchu z bazą znanych wzorców ataków, takich jak charakterystyczne ciągi znaków w pakietach. Analiza behawioralna i anomalii pozwala na wykrywanie nieznanych wcześniej zagrożeń poprzez identyfikację odchyleń od normalnego wzorca ruchu sieciowego. Zaawansowane systemy IPS wykorzystują uczenie maszynowe do ciągłego doskonalenia skuteczności wykrywania nowych typów ataków.
Analiza protokołów w systemie IPS polega na weryfikacji zgodności transmisji ze specyfikacją danego protokołu, co pozwala wykryć ataki wykorzystujące nietypowe struktury pakietów. System IPS może działać w trybie inline, gdzie cały ruch przepływa przez urządzenie, lub w trybie monitorowania pasywnego z wykorzystaniem zwierciadlanego portu. Skuteczność systemu zapobiegania włamaniom zależy od aktualności baz sygnatur oraz prawidłowego dostrojenia czułości detekcji. Zbyt restrykcyjne reguły mogą prowadzić do fałszywych alarmów i blokowania legalnego ruchu, natomiast zbyt liberalne reguły mogą przepuszczać realne zagrożenia. Integracja IPS z zaporą nowej generacji pozwala na skoordynowaną reakcję na incydenty bezpieczeństwa w jednym urządzeniu.
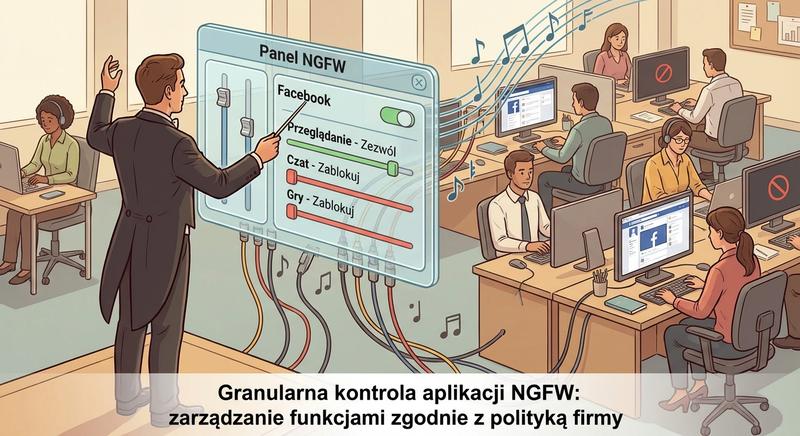
Kontrola aplikacji (Application Control) to funkcja NGFW, która pozwala identyfikować i zarządzać ruchem sieciowym na poziomie poszczególnych aplikacji, a nie tylko portów i protokołów. W dzisiejszych sieciach wiele aplikacji używa standardowych portów (80/443) do maskowania swojego ruchu.
Administrator może tworzyć polityki zezwalające lub blokujące konkretne aplikacje, np. zezwolić na WhatsApp Web, ale zablokować Facebook Messenger. Kontrola działa niezależnie od portu – DPI analizuje sygnatury aplikacji w payloadzie ruchu. Zaawansowane NGFW potrafią również kontrolować poszczególne funkcje w ramach jednej aplikacji (np. zezwolić na odczyt plików w SharePoint, ale zablokować upload) dzięki integracji z API aplikacji chmurowych.
Kontrola aplikacji w zaporze nowej generacji umożliwia identyfikację ruchu sieciowego na poziomie konkretnych programów, niezależnie od portu czy protokołu użytego do transmisji. Mechanizm ten wykorzystuje głęboką inspekcję pakietów do analizy charakterystycznych sygnatur aplikacji, takich jak wzorce w nagłówkach HTTP czy specyficzne sekwencje bajtów. Dzięki kontroli aplikacji administrator może zezwolić na korzystanie z Facebooka, ale zablokować wbudowane w niego gry, co byłoby niemożliwe przy filtrowaniu wyłącznie adresów IP i portów. Zapora potrafi rozpoznać setki różnych aplikacji i usług, od komunikatorów po narzędzia do zdalnego dostępu i platformy streamingowe. Po zidentyfikowaniu aplikacji administrator może zastosować wobec niej szczegółowe polityki bezpieczeństwa, w tym ograniczenia pasma i blokowanie określonych funkcji.
Kontrola aplikacji jest szczególnie przydatna w środowiskach korporacyjnych, gdzie pracownicy mogą próbować omijać blokady, używając niestandardowych portów lub tunelowania ruchu. Zapora nowej generacji potrafi odróżnić legalny ruch HTTP na porcie 80 od ruchu innej aplikacji przepuszczonego przez ten sam port. Mechanizm ten pozwala również na wykrywanie i blokowanie protokołów tunelujących, takich jak VPN-y stworzone w celu ominięcia firmowych polityk bezpieczeństwa. Szczegółowe raporty generowane przez moduł kontroli aplikacji dostarczają informacji o tym, które programy są najczęściej używane w sieci. Dzięki temu administrator może podejmować świadome decyzje o optymalizacji wykorzystania pasma i dostosowaniu polityk bezpieczeństwa.
Web Application Firewall (WAF) to wyspecjalizowany typ firewalla chroniący aplikacje internetowe przed atakami na poziomie warstwy 7. W przeciwieństwie do tradycyjnych zapór sieciowych, WAF rozumie protokół HTTP/HTTPS i potrafi analizować treść żądań oraz odpowiedzi.
- Ochrona przed OWASP Top 10: SQL Injection, Cross-Site Scripting (XSS), Cross-Site Request Forgery (CSRF), niebezpieczne deserializacje.
- Metody działania: Pozytywny model (whitelisting – zezwala tylko na znane, poprawne żądania) lub negatywny model (blacklisting – blokuje znane wzorce ataków).
- WAF może być: sieciowy (inline – analizuje cały ruch), hostowy (moduł aplikacji serwera, np. ModSecurity dla Apache) lub chmurowy (Cloudflare, AWS WAF, Azure WAF).
Zapora aplikacyjna typu WAF jest wyspecjalizowanym urządzeniem lub oprogramowaniem chroniącym aplikacje internetowe przed atakami wymierzonymi w warstwę siódmą modelu OSI. Głównym zadaniem WAF jest ochrona przed zagrożeniami z listy OWASP Top 10, w tym wstrzykiwaniem kodu SQL, atakami XSS i podrabianiem żądań międzywitrynowych. Zapora aplikacyjna może działać w modelu pozytywnym, który zezwala wyłącznie na jawnie dozwolone żądania, lub w modelu negatywnym blokującym znane wzorce ataków. WAF może być wdrożony jako urządzenie sieciowe, oprogramowanie instalowane na serwerze lub usługa w chmurze obliczeniowej. Wdrożenie WAF w chmurze jest szczególnie popularne w przypadku aplikacji hostowanych w środowiskach chmurowych, ponieważ nie wymaga instalacji dodatkowego sprzętu.
Zapora aplikacyjna analizuje żądania HTTP i HTTPS, sprawdzając poprawność parametrów, nagłówków i treści przesyłanych do aplikacji internetowej. WAF potrafi blokować próby obejścia uwierzytelnienia, ataki słownikowe na formularze logowania oraz skrypty pobierane z zewnętrznych źródeł. Zaawansowane zapory aplikacyjne wykorzystują mechanizmy uczenia maszynowego do budowania modeli normalnego ruchu i wykrywania odchyleń mogących świadczyć o ataku. Reguły WAF można dostosowywać do specyfiki chronionej aplikacji, co zwiększa skuteczność ochrony i zmniejsza liczbę fałszywych alarmów. WAF stanowi niezbędny element zabezpieczenia każdej nowoczesnej aplikacji internetowej narażonej na ataki z sieci publicznej.
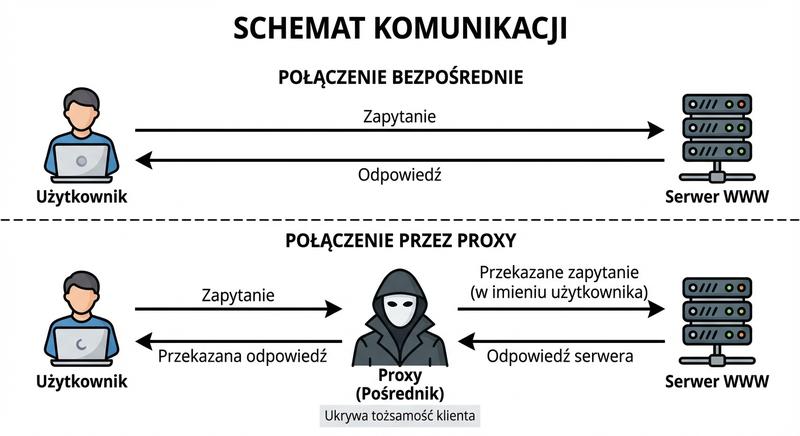
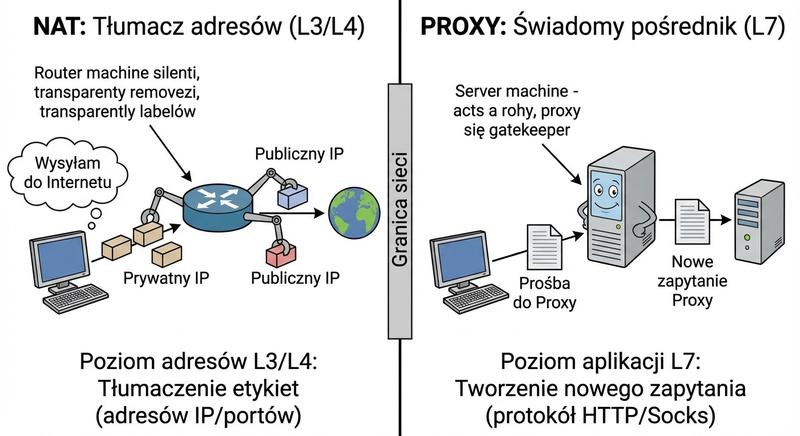
Serwer proxy (pełnomocnik) to urządzenie lub oprogramowanie, które pośredniczy w komunikacji między klientem a serwerem docelowym. Gdy klient chce uzyskać dostęp do zasobu internetowego, najpierw wysyła żądanie do proxy, a dopiero proxy przekazuje je do właściwego serwera.
Proxy działa na warstwie 7 (aplikacji) i może rozumieć protokoły takie jak HTTP, HTTPS, FTP czy SOCKS. Dzięki temu może nie tylko przekazywać ruch, ale również go modyfikować, buforować (caching), filtrować i anonimizować. Proxy forward (tradycyjne) obsługuje ruch wychodzący (klienci LAN do Internetu), a reverse proxy (odwrotne) obsługuje ruch przychodzący (Internet do serwerów w DMZ).
Serwer proxy jest urządzeniem lub programem pośredniczącym w komunikacji między klientem a serwerem docelowym, działającym głównie w siódmej warstwie modelu OSI. W zależności od konfiguracji proxy może obsługiwać ruch wychodzący z sieci wewnętrznej do internetu, czyli pełnić funkcję proxy przychodzącego, lub kierować ruch z internetu do serwerów wewnętrznych, działając jako odwrotne proxy. Serwer proxy przyspiesza działanie sieci dzięki buforowaniu często odwiedzanych stron internetowych i przechowywaniu ich w pamięci podręcznej. Mechanizm filtrowania treści w proxy pozwala na blokowanie dostępu do niepożądanych witryn na podstawie kategorii, adresów URL lub zawartości stron. Proxy może również ukrywać adresy IP urządzeń wewnętrznych, zastępując je własnym adresem i zwiększając w ten sposób anonimowość użytkowników.
Odwrotne proxy jest powszechnie stosowane w architekturach serwerowych do równoważenia obciążenia między wieloma serwerami aplikacyjnymi. Serwer proxy może rejestrować cały ruch przechodzący przez urządzenie, co ułatwia audyt bezpieczeństwa i analizę zdarzeń sieciowych. W firmowych sieciach proxy często integruje się z systemami uwierzytelniania, co pozwala na przypisanie ruchu do konkretnych użytkowników. Nowoczesne serwery proxy potrafią również modyfikować przesyłane treści, na przykład wstrzykiwać nagłówki bezpieczeństwa lub kompresować dane przed wysłaniem do klienta. Wdrożenie serwera proxy jest szczególnie zalecane w organizacjach, gdzie istotne są kontrola dostępu do internetu i optymalizacja wykorzystania łącza sieciowego.
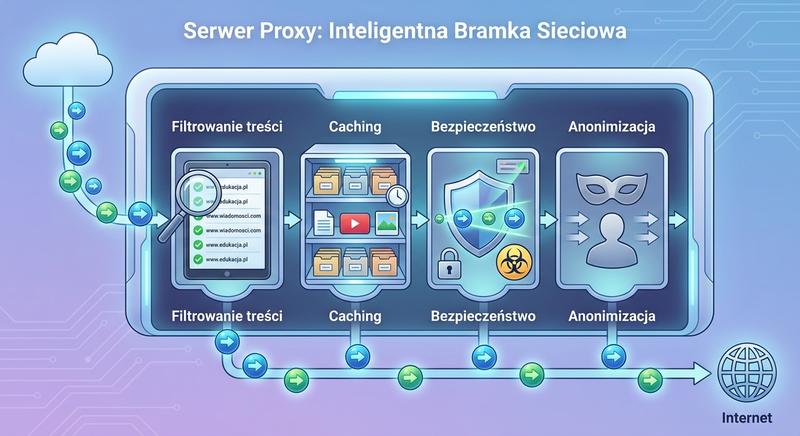
Serwer proxy oferuje szereg funkcji wykraczających poza zwykłe przekazywanie ruchu, co czyni go niezwykle użytecznym narzędziem w sieciach korporacyjnych i operatorskich.
- Caching (buforowanie): Proxy przechowuje lokalne kopie często odwiedzanych stron. Kolejne żądania o ten sam zasób są obsługiwane z pamięci podręcznej, co znacząco przyspiesza ładowanie i oszczędza pasmo.
- Kontrola dostępu i filtrowanie: Proxy może blokować dostęp do określonych kategorii stron (pornografia, social media, hazard) na podstawie URL, treści lub kategorii.
- Anonimizacja i ukrywanie sieci wewnętrznej: Serwer docelowy widzi adres IP proxy, a nie faktycznego klienta. Proxy może również modyfikować nagłówki HTTP, usuwając informacje o systemie operacyjnym i przeglądarce.
Pamięć podręczna serwera proxy przechowuje lokalne kopie często odwiedzanych stron internetowych, co znacząco przyspiesza ich wczytywanie przy kolejnych wizytach użytkowników. Mechanizm buforowania zmniejsza obciążenie łącza sieciowego, ponieważ wiele żądań jest obsługiwanych bez konieczności pobierania danych z internetu. Kontrola dostępu realizowana przez proxy pozwala na blokowanie stron zawierających treści nieodpowiednie lub niezgodne z polityką bezpieczeństwa organizacji. Filtrowanie adresów URL i kategorii witryn odbywa się na podstawie regularnie aktualizowanych baz danych prowadzonych przez wyspecjalizowane firmy. Proxy może rejestrować historię przeglądania wszystkich użytkowników, co jest wykorzystywane do celów audytowych i analizy incydentów bezpieczeństwa.
Funkcja anonimizacji w serwerze proxy polega na ukrywaniu prawdziwego adresu IP klienta przed serwerem docelowym, co utrudnia śledzenie aktywności użytkownika. W sieciach firmowych proxy umożliwia scentralizowane zarządzanie politykami dostępu do internetu bez konieczności konfigurowania każdego urządzenia końcowego z osobna. Serwery proxy mogą również modyfikować nagłówki żądań HTTP, na przykład dodawać informacje o uwierzytelnieniu użytkownika lub usuwać nagłówki ujawniające szczegóły techniczne klienta. Zaawansowane proxy potrafią analizować zawartość pobieranych plików i blokować te zawierające złośliwy kod lub naruszające politykę organizacji. Wdrożenie serwera proxy jest stosunkowo proste i przynosi wymierne korzyści zarówno w zakresie bezpieczeństwa, jak i wydajności sieci.
Na pierwszy rzut oka proxy i NAT (Network Address Translation) mogą wydawać się podobne – oba ukrywają wewnętrzne adresy IP. Różnice są jednak fundamentalne i dotyczą warstwy działania oraz zakresu funkcjonalności.
NAT działa na warstwie 3 (sieciowej) i modyfikuje adresy IP w nagłówkach pakietów. Jest przezroczysty dla aplikacji – nie wymaga konfiguracji po stronie klienta. Proxy działa na warstwie 7 (aplikacji) i jest świadome protokołów – wymaga konfiguracji w przeglądarce lub systemie operacyjnym. NAT po prostu zmienia adresy, podczas gdy proxy może analizować, modyfikować i buforować treść. Co ważne, NAT nie anonimizuje ruchu tak skutecznie jak proxy (NAT nie usuwa nagłówków HTTP, cookies itp.). We współczesnych sieciach często spotyka się transparentne proxy, które łączy cechy obu rozwiązań – działa na L7 jak proxy, ale nie wymaga konfiguracji klienta (przechwytuje ruch przez NAT/route).
NAT działa na trzeciej warstwie modelu OSI i modyfikuje adresy IP w nagłówkach pakietów, będąc całkowicie przezroczystym dla aplikacji i niewymagającym konfiguracji po stronie klienta. Proxy natomiast operuje na siódmej warstwie aplikacji, rozumiejąc protokoły takie jak HTTP i FTP, co umożliwia mu analizowanie i modyfikowanie treści przesyłanych danych. W przeciwieństwie do NAT, który jedynie podmienia adresy, proxy może buforować często odwiedzane strony, filtrować niepożądane treści oraz blokować określone kategorie witryn. NAT nie anonimizuje ruchu tak skutecznie jak proxy, ponieważ nie usuwa nagłówków HTTP ani ciasteczek, które mogą ujawnić tożsamość użytkownika. Transparentne proxy łączy zalety obu rozwiązań, działając na siódmej warstwie jak proxy, ale nie wymagając konfiguracji klienta, ponieważ przechwytuje ruch przez mechanizm NAT lub przekierowanie na routerze.
W praktyce sieciowej NAT jest powszechnie stosowany w routerach domowych i firmowych do udostępniania jednego publicznego adresu IP wielu urządzeniom w sieci wewnętrznej. Proxy znajduje zastosowanie przede wszystkim w środowiskach korporacyjnych, gdzie konieczne jest centralne zarządzanie dostępem do internetu i kontrola treści odwiedzanych przez pracowników. Transparentne proxy jest często wykorzystywane w sieciach hotspotów i szkolnych, gdzie użytkownicy nie mogą lub nie powinni samodzielnie konfigurować ustawień proxy w przeglądarce. Połączenie NAT i proxy w jednym urządzeniu pozwala na elastyczne zarządzanie ruchem wychodzącym z sieci przy jednoczesnym zachowaniu przezroczystości dla użytkownika końcowego. Wybór między NAT a proxy zależy od konkretnych wymagań dotyczących bezpieczeństwa, wydajności i kontroli treści w danej infrastrukturze sieciowej.
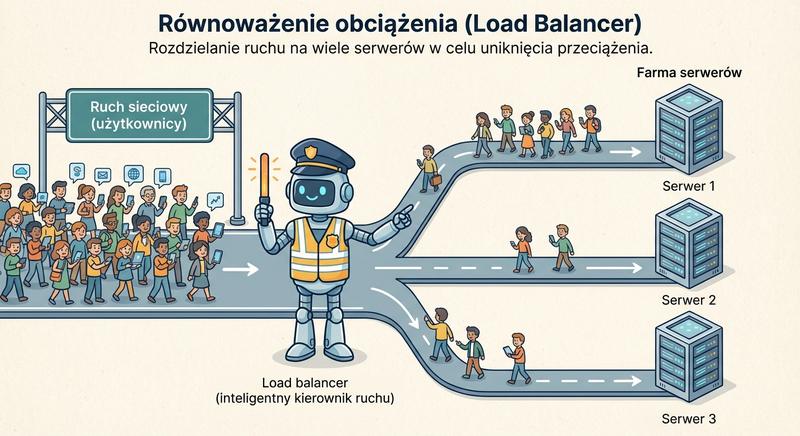
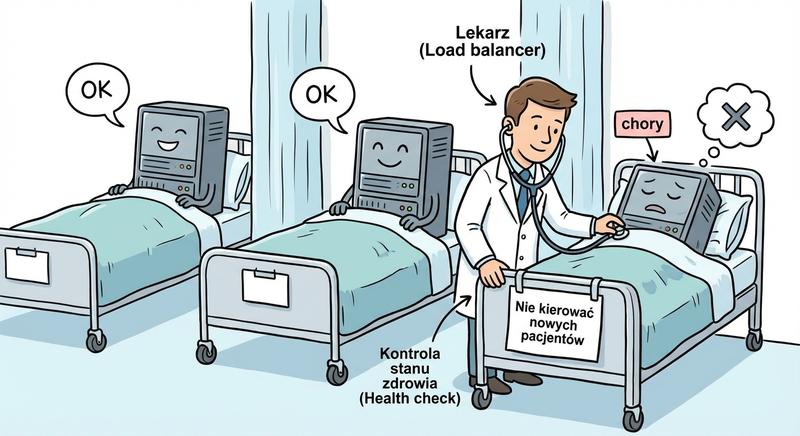
Load Balancer (równoważnik obciążenia) to urządzenie lub oprogramowanie, które dystrybuuje ruch sieciowy na wiele serwerów zaplecza (backend). Jego głównym celem jest zapewnienie wysokiej dostępności (HA), skalowalności i optymalnego wykorzystania zasobów.
Load Balancer działa na zasadzie wirtualnego serwera (Virtual IP – VIP). Klienci łączą się z adresem VIP, a load balancer decyduje, który fizyczny serwer (Real Server) ma obsłużyć żądanie. W przypadku awarii jednego z serwerów, ruch jest automatycznie kierowany na pozostałe. Load balancery mogą działać zarówno jako dedykowane urządzenia sprzętowe (F5 BIG-IP, Citrix ADC) jak i programowe (HAProxy, NGINX, Linux Virtual Server).
Load balancer to urządzenie lub oprogramowanie dystrybuujące ruch sieciowy na wiele serwerów zaplecza w celu zapewnienia wysokiej dostępności i optymalnego wykorzystania zasobów. Klienci łączą się z wirtualnym adresem IP zwanym VIP, a load balancer decyduje, który fizyczny serwer z puli realnych serwerów ma obsłużyć dane żądanie. W przypadku awarii jednego z serwerów ruch jest automatycznie przekierowywany na pozostałe, co gwarantuje ciągłość działania usług bez przerw dla użytkowników końcowych. Rozwiązania sprzętowe takie jak F5 BIG-IP i Citrix ADC oferują dedykowane układy ASIC przyspieszające przetwarzanie pakietów, co sprawdza się w środowiskach o bardzo wysokim natężeniu ruchu. Rozwiązania programowe, w tym HAProxy, NGINX i Linux Virtual Server, są popularne ze względu na niższy koszt i elastyczność konfiguracji w środowiskach chmurowych i wirtualizowanych.
Load balancer pełni również funkcję warstwy abstrakcji między klientami a serwerami, ukrywając topologię wewnętrzną sieci przed światem zewnętrznym. Dzięki mechanizmom health check load balancer może automatycznie wyłączać z puli serwery, które uległy awarii lub nie odpowiadają na zapytania w zadanym czasie. W nowoczesnych architekturach mikroserwisowych load balancery są niezbędne do równoważenia ruchu między wieloma instancjami tej samej usługi uruchomionymi w kontenerach. Skalowalność horyzontalna osiągana przez dodawanie kolejnych serwerów za load balancerem jest jednym z fundamentów architektur chmurowych i aplikacji internetowych o wysokiej dostępności. Integracja load balancera z systemami monitoringu i automatycznego skalowania pozwala na dynamiczne dostosowywanie mocy obliczeniowej do aktualnego obciążenia.
Mechanizm działania load balancera opiera się na kilku kluczowych komponentach i procesach, które współdziałają, aby zapewnić niezawodne i wydajne rozłożenie ruchu.
Podstawowym elementem jest Virtual IP (VIP) – adres IP widoczny dla klientów. Za VIP-em stoi pula serwerów rzeczywistych (Real Servers). Load balancer przechwytuje przychodzące pakiety, a następnie na podstawie wybranego algorytmu wybiera serwer docelowy. W zależności od konfiguracji, load balancer może modyfikować pakiety (zmieniać adresy IP i porty) lub bezpośrednio przekazywać je do serwera (np. w trybie DSR – Direct Server Return). Dla zapewnienia spójności, load balancer utrzymuje tablicę translacji (NAT table), mapującą oryginalne połączenia klientów na wybrane serwery backendu.
Podstawowym elementem działania load balancera jest wirtualny adres IP, który jest widoczny dla klientów i stanowi punkt wejścia do usługi, podczas gdy rzeczywiste serwery pozostają ukryte za urządzeniem równoważącym. Load balancer przechwytuje przychodzące pakiety i na podstawie wybranego algorytmu, na przykład round robin lub najmniejszej liczby połączeń, wybiera serwer docelowy z puli realnych serwerów. W trybie NAT load balancer modyfikuje docelowy adres IP i port w pakiecie, przekierowując go do wybranego serwera, a następnie odwraca translację dla ruchu powrotnego. W trybie DSR serwer odpowiada bezpośrednio klientowi z pominięciem load balancera, co zmniejsza obciążenie urządzenia równoważącego i poprawia wydajność przy dużym ruchu. Load balancer utrzymuje tablicę translacji NAT, która mapuje oryginalne połączenie klienta na wybrany serwer backendu, co jest niezbędne do zachowania spójności sesji.
Każde nowe połączenie przychodzące na VIP jest analizowane przez load balancer, który na podstawie algorytmu wybiera optymalny serwer i tworzy wpis w tablicy translacji dla przyszłych pakietów tego samego strumienia. Tablica translacji pozwala load balancerowi kierować wszystkie pakiety należące do jednego połączenia na ten sam serwer, co jest kluczowe dla aplikacji stanowych takich jak koszyki sklepowe czy systemy bankowości internetowej. W przypadku awarii load balancera kluczowe jest zastosowanie konfiguracji active-standby z synchronizacją tablic translacji, aby przejęcie ruchu przez zapasowe urządzenie było bezproblemowe. Zaawansowane load balancery oferują również możliwość definiowania reguł persistencji sesji na podstawie ciasteczek, adresów IP czy identyfikatorów SSL. Monitorowanie obciążenia poszczególnych serwerów i dynamiczne dostosowywanie wag algorytmów pozwala na optymalne wykorzystanie zasobów w zmiennych warunkach ruchu.
Load balancer może wybierać serwer docelowy na podstawie różnych algorytmów, które decydują o sposobie dystrybucji ruchu. Wybór odpowiedniego algorytmu zależy od charakterystyki aplikacji.
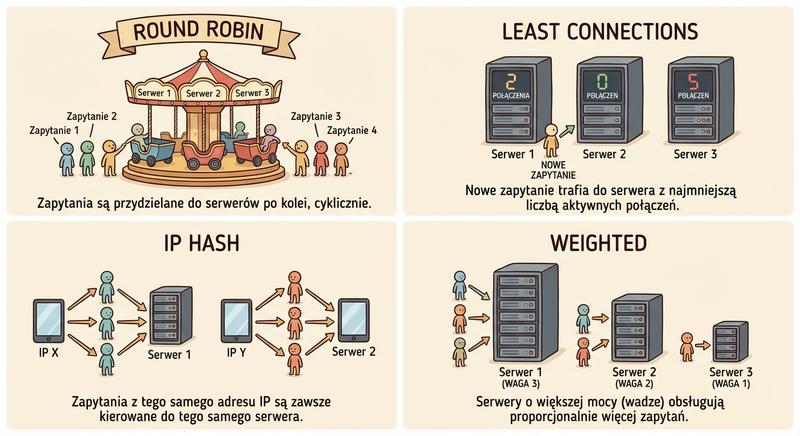
- Round Robin: Żądania są kierowane po kolei do każdego serwera z puli. Prosty i sprawiedliwy, ale nie uwzględnia obciążenia serwerów.
- Least Connections: Nowe żądanie trafia do serwera z najmniejszą liczbą aktywnych połączeń. Sprawdza się przy zmiennym czasie trwania sesji.
- Source IP Hash: Na podstawie adresu IP klienta (lub jego hasha) wybierany jest zawsze ten sam serwer. Kluczowe dla session persistence.
- Weighted Round Robin / Weighted Least Connections: Warianty ważone – serwery o większej mocy otrzymują proporcjonalnie więcej ruchu.
Algorytm round robin to najprostsza metoda dystrybucji ruchu, w której żądania są kierowane po kolei do każdego serwera z puli bez uwzględniania ich aktualnego obciążenia. Algorytm najmniejszej liczby połączeń kieruje nowe żądanie do serwera z najmniejszą liczbą aktywnych sesji, co sprawdza się dobrze przy zmiennym czasie trwania połączeń. Algorytm haszowania adresu źródłowego IP zapewnia, że wszystkie żądania od danego klienta trafiają na ten sam serwer, co jest kluczowe dla utrzymania sesji w aplikacjach nieobsługujących ciasteczek. Warianty ważone tych algorytmów pozwalają przypisać serwerom o większej mocy obliczeniowej proporcjonalnie więcej ruchu, co optymalizuje wykorzystanie zróżnicowanego sprzętu. Wybór odpowiedniego algorytmu zależy od charakterystyki aplikacji, długości trwania sesji oraz równomierności obciążenia generowanego przez poszczególnych użytkowników.
Round Robin sprawdza się doskonale w przypadku aplikacji bezstanowych, gdzie każde żądanie jest niezależne i może być obsłużone przez dowolny serwer w puli. Least Connections jest preferowany w środowiskach, gdzie sesje mają bardzo zróżnicowany czas trwania, na przykład w aplikacjach bazodanowych lub sklepach internetowych. Source IP Hash jest nieoceniony w sytuacjach, gdy aplikacja nie obsługuje mechanizmów persistencji sesji na poziomie warstwy aplikacji, na przykład w starszych systemach legacy. Niektóre zaawansowane load balancery oferują algorytmy adaptacyjne, które na podstawie ciągłego monitorowania wydajności serwerów dynamicznie dostosowują rozkład ruchu. W praktyce produkcyjnej często stosuje się kombinację algorytmów, na przykład round robin ważony jako domyślny z mechanizmem persistencji sesji opartym na ciasteczkach.
Load balancery można podzielić na dwa główne typy w zależności od warstwy, na której podejmują decyzje o przekierowaniu ruchu. Różnica między L4 a L7 ma istotne konsekwencje dla funkcjonalności i wydajności.
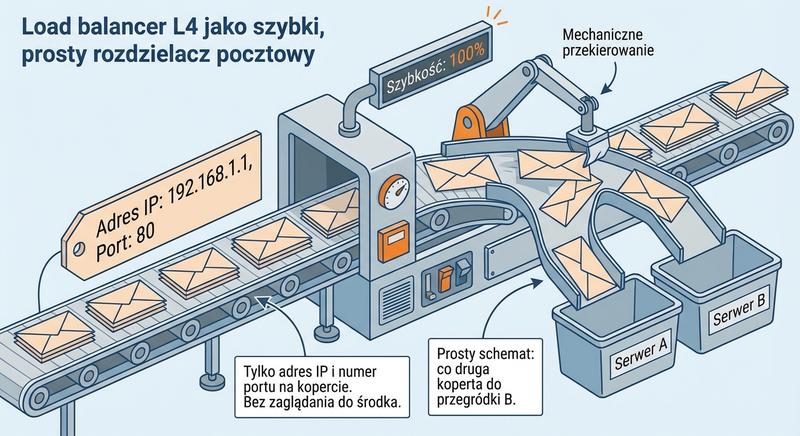
Load Balancer L4 (warstwa transportowa): Działa na podstawie adresów IP i portów TCP/UDP. Nie analizuje treści pakietów – jest szybki i lekki. Idealny do ruchu, gdzie nie jest potrzebne zaawansowane routowanie na podstawie treści (np. równoważenie połączeń MySQL, VPN).
Load Balancer L7 (warstwa aplikacji): Analizuje treść żądań, np. nagłówki HTTP, URL, cookies, treść XML/JSON. Umożliwia zaawansowane routowanie (np. /api/* na jeden pul serwerów, /static/* na inny). Potrafi modyfikować treść (rewrite URL) i wykonywać SSL offloading. Daje więcej możliwości, ale kosztem większej złożoności i wyższego zużycia CPU.
Load balancer warstwy czwartej podejmuje decyzje routingowe wyłącznie na podstawie adresów IP i portów TCP lub UDP, nie analizując zawartości przesyłanych pakietów. Dzięki temu jest wyjątkowo szybki i lekki, ponieważ nie musi dekapsulować ani analizować treści warstwy aplikacji, co minimalizuje opóźnienia i zużycie zasobów. Jest idealnym rozwiązaniem dla równoważenia ruchu baz danych, połączeń VPN oraz innych protokołów, gdzie nie jest potrzebna analiza treści żądań. Load balancer warstwy siódmej analizuje nagłówki HTTP, adresy URL, ciasteczka oraz treść XML i JSON, umożliwiając zaawansowane routowanie na podstawie treści. Dzięki temu możliwe jest kierowanie ruchu do różnych pul serwerów w zależności od ścieżki URL, na przykład zapytań API do serwerów aplikacyjnych i plików statycznych do serwerów cache.
Load balancer L7 potrafi modyfikować treść żądań i odpowiedzi, na przykład przepisywać adresy URL, dodawać lub usuwać nagłówki HTTP oraz kompresować dane przed wysłaniem do klienta. Ponadto urządzenia warstwy siódmej mogą wykonywać odciążanie SSL, dekryptując ruch TLS przed przekazaniem go do serwerów backendu w postaci zwykłego HTTP. Kosztem tych zaawansowanych funkcji jest wyższe zużycie procesora i większe opóźnienie w porównaniu z load balancerem L4, co ma znaczenie przy bardzo dużym natężeniu ruchu. W praktyce wiele nowoczesnych load balancerów oferuje zarówno tryb L4, jak i L7, umożliwiając administratorowi wybór odpowiedniego poziomu w zależności od konkretnej aplikacji. W środowiskach produkcyjnych często stosuje się hybrydowe podejście, w którym ruch przechodzi najpierw przez szybki balanser L4, a następnie wybrane strumienie są kierowane do analizy L7.
Dwa kluczowe mechanizmy, bez których load balancer nie mógłby prawidłowo funkcjonować w środowisku produkcyjnym, to health checks (badanie stanu) i session persistence (utrzymanie sesji).
Health Checks: Load balancer regularnie sprawdza dostępność serwerów backendu, wysyłając zapytania (np. ping ICMP, próba połączenia TCP, żądanie HTTP GET pod określony URL). Jeśli serwer nie odpowie w zadanym czasie lub zwróci kod błędu (np. 5xx), jest automatycznie wyłączany z puli (mark as down). Po przywróceniu sprawności – włączany z powrotem.
Session Persistence (lepkość sesji): Niektóre aplikacje (np. koszyki sklepowe) wymagają, aby wszystkie żądania od jednego klienta trafiały na ten sam serwer. Metody utrzymania sesji to: Source IP Affinity (to samo IP = ten sam serwer), Cookie Insert (LB wstrzykuje cookie z identyfikatorem serwera) lub SSL Session ID.
Mechanizm health check polega na regularnym wysyłaniu zapytań do serwerów backendu w celu sprawdzenia ich dostępności i gotowości do przyjmowania ruchu. Najprostsze testy to ping ICMP sprawdzający ogólną dostępność serwera oraz próba połączenia TCP na określony port, która weryfikuje, czy usługa nasłuchuje. Zaawansowane health checki HTTP wysyłają żądanie GET pod konkretny URL i oczekują odpowiedzi z kodem 200 OK, co potwierdza pełną sprawność aplikacji. Jeśli serwer nie odpowie w zadanym czasie lub zwróci kod błędu, jest automatycznie wyłączany z puli, a ruch jest kierowany na pozostałe działające serwery, co zapewnia nieprzerwane działanie usługi. Po przywróceniu sprawności serwer jest automatycznie włączany z powrotem do puli, bez konieczności ręcznej interwencji administratora.
Session persistence, zwana również lepkością sesji, zapewnia, że wszystkie żądania od jednego klienta trafiają na ten sam serwer, co jest kluczowe dla aplikacji przechowujących stan sesji lokalnie. Metoda Source IP affinity polega na haszowaniu adresu IP klienta i przypisaniu go do konkretnego serwera, ale może powodować nierównomierne obciążenie przy ruchu z dużych sieci NAT. Cookie Insert polega na wstrzyknięciu przez load balancer ciasteczka zawierającego identyfikator serwera, które przeglądarka klienta odsyła przy kolejnych żądaniach. Metoda SSL Session ID wykorzystuje identyfikator sesji TLS jako klucz persistencji, co jest eleganckim rozwiązaniem dla ruchu szyfrowanego. W nowoczesnych architekturach aplikacji problem persistencji rozwiązuje się na poziomie aplikacji poprzez przechowywanie stanu sesji w zewnętrznych magazynach danych, takich jak Redis lub Memcached.
SSL Offloading (zwany też SSL Termination) to proces odciążania serwerów aplikacyjnych z kosztownego obliczeniowo szyfrowania i deszyfrowania ruchu TLS/SSL. Zadanie to przejmuje load balancer lub inne dedykowane urządzenie.
Mechanizm jest prosty: load balancer nawiązuje szyfrowane połączenie TLS z klientem (zewnętrzny ruch HTTPS), a następnie dekryptuje ruch i przekazuje go do serwerów backendu jako zwykły HTTP (niezaszyfrowany). Dzięki temu serwery backendu nie muszą wykonywać kosztownych operacji kryptograficznych, co znacząco zwiększa ich wydajność. Load balancer może być również miejscem centralnego zarządzania certyfikatami SSL. Bezpieczeństwo transmisji między LB a serwerami backendu może być zapewnione przez izolację sieci (VLAN, sieć prywatna). Wariantem jest SSL Bridging (LB deszyfruje i ponownie szyfruje) oraz re-encryption (pełne szyfrowanie end-to-end).
SSL Offloading to proces przeniesienia kosztownych obliczeniowo operacji szyfrowania i deszyfrowania ruchu TLS z serwerów aplikacyjnych na load balancer lub inne dedykowane urządzenie. Load balancer nawiązuje szyfrowane połączenie TLS z klientem, a następnie dekryptuje ruch i przekazuje go do serwerów backendu jako zwykły HTTP, co znacząco odciąża procesory serwerów. Dzięki temu serwery mogą obsłużyć znacznie więcej żądań na sekundę, ponieważ nie muszą wykonywać kosztownych operacji kryptograficznych dla każdego połączenia. Load balancer staje się centralnym miejscem zarządzania certyfikatami SSL, co upraszcza administrację i eliminuje konieczność instalowania certyfikatów na każdym serwerze z osobna. Bezpieczeństwo transmisji między load balancerem a serwerami backendu jest zazwyczaj zapewniane przez izolację fizyczną sieci poprzez dedykowane VLAN-y lub sieci prywatne.
Wariant SSL Bridging polega na tym, że load balancer deszyfruje ruch, a następnie ponownie szyfruje go przed wysłaniem do serwera backendu, co zapewnia szyfrowanie end-to-end przy jednoczesnym odciążeniu serwerów. SSL Offloading jest szczególnie zalecany w środowiskach, gdzie certyfikaty TLS są często wymieniane lub gdzie obowiązują scentralizowane polityki bezpieczeństwa dotyczące zarządzania kluczami. W chmurze obliczeniowej usługi takie jak AWS Elastic Load Balancer oferują wbudowane wsparcie dla SSL Termination, co eliminuje konieczność konfigurowania certyfikatów na instancjach aplikacji. Należy pamiętać, że po odszyfrowaniu ruchu między load balancerem a serwerem backendu dane są przesyłane w postaci jawnej, co wymaga odpowiednich zabezpieczeń sieci wewnętrznej. Niektóre aplikacje wymagają kompleksowego szyfrowania ze względów regulacyjnych, na przykład w sektorze finansowym lub medycznym, co wyklucza zastosowanie standardowego SSL Offloading.
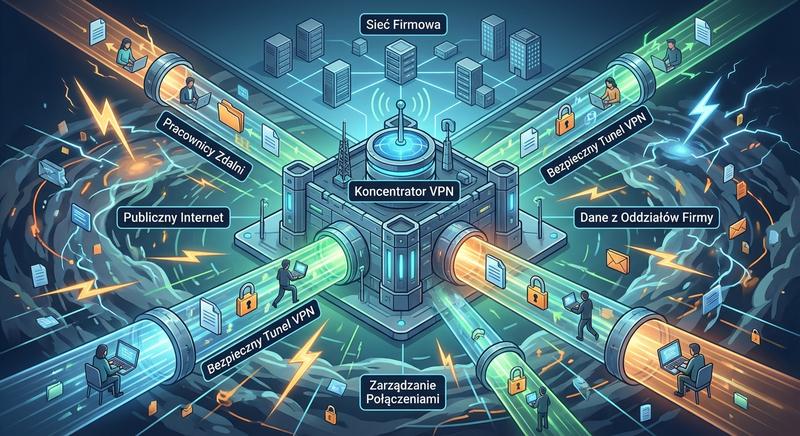
Koncentrator VPN (VPN Concentrator) to dedykowane urządzenie lub moduł routera/firewalla, który umożliwia nawiązywanie bezpiecznych połączeń VPN (Virtual Private Network) przez publiczną sieć, taką jak Internet. Jest to urządzenie kończące wiele równoczesnych tuneli VPN.
Koncentrator VPN obsługuje różne protokoły tunelowania, takie jak IPsec (najpopularniejszy w połączeniach site-to-site i remote access), SSL/TLS VPN (OpenVPN, AnyConnect – wygodne dla użytkowników mobilnych), L2TP, PPTP (przestarzały) oraz WireGuard (nowoczesny, lekki protokół). Urządzenie to odpowiada za negocjację parametrów połączenia, uwierzytelnianie użytkowników (np. poprzez RADIUS/LDAP), szyfrowanie i deszyfrowanie ruchu oraz zarządzanie politykami dostępu do sieci wewnętrznej. Wiele nowoczesnych firewalli NGFW ma wbudowaną funkcję koncentratora VPN.
Koncentrator VPN to dedykowane urządzenie lub moduł routera albo firewalla, który umożliwia nawiązywanie bezpiecznych połączeń VPN przez publiczną sieć Internet dla wielu równoczesnych użytkowników. Urządzenie to obsługuje różne protokoły tunelowania, w tym IPsec jako najpopularniejszy dla połączeń typu site-to-site i zdalnego dostępu, SSL oraz TLS stosowane w rozwiązaniach takich jak OpenVPN i Cisco AnyConnect. Coraz większą popularność zdobywa WireGuard jako nowoczesny, lekki protokół VPN oferujący prostszą konfigurację i wyższą wydajność niż tradycyjne rozwiązania. Koncentrator odpowiada za negocjację parametrów połączenia, uwierzytelnianie użytkowników poprzez mechanizmy takie jak RADIUS czy LDAP oraz szyfrowanie i deszyfrowanie całego ruchu przechodzącego przez tunel. Wiele nowoczesnych zapór NGFW ma wbudowaną funkcję koncentratora VPN, co eliminuje konieczność stosowania oddzielnych urządzeń do obsługi zdalnego dostępu.
W przypadku połączeń site-to-site koncentrator VPN łączy ze sobą całe sieci lokalne oddzielonych geograficznie oddziałów firmy, tworząc jednolitą, bezpieczną sieć rozległą. Dla użytkowników mobilnych koncentrator VPN oferuje możliwość bezpiecznego połączenia z siecią firmową z dowolnego miejsca na świecie, co jest niezbędne w modelu pracy zdalnej. Zaawansowane koncentratory VPN oferują funkcje podwójnego uwierzytelniania, integrację z systemami zarządzania tożsamością oraz szczegółowe logowanie aktywności użytkowników. Protokół L2TP, często łączony z IPsec w celu zapewnienia szyfrowania, jest wciąż spotykany w starszych implementacjach, podczas gdy nowe wdrożenia preferują SSL VPN lub WireGuard. Koncentratory VPN nowej generacji potrafią również analizować ruch w tunelu pod kątem zagrożeń i stosować polityki bezpieczeństwa niezależne dla każdego użytkownika.
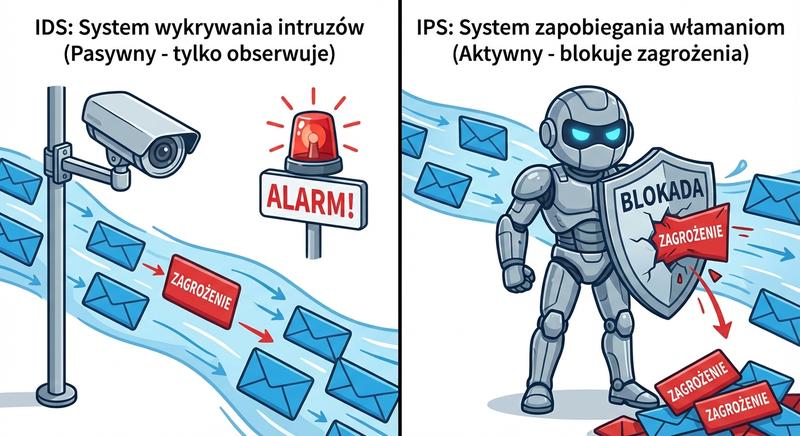
Systemy wykrywania i zapobiegania włamaniom (IDS/IPS) to kluczowe elementy bezpieczeństwa służące do monitorowania ruchu sieciowego pod kątem złośliwej aktywności. Różnica między IDS a IPS polega na sposobie reakcji na zagrożenie.
- IDS (Intrusion Detection System): Działa w trybie pasywnym (out-of-band) – monitoruje kopię ruchu (np. przez port SPAN/monitor na switchu). Generuje alarmy i raporty, ale nie blokuje ruchu w czasie rzeczywistym. Przydatny do analizy forensycznej i audytu.
- IPS (Intrusion Prevention System): Działa w trybie aktywnym (inline) – znajduje się bezpośrednio na ścieżce ruchu. Może blokować pakiety, resetować połączenia, odrzucać złośliwy ruch w czasie rzeczywistym.
- Metody detekcji: Sygnaturowe (pattern matching – porównanie z bazą wzorców), Anomalii (profilowanie normalnego ruchu), Stanu protokołu (protocol state analysis – wykrywanie naruszeń specyfikacji RFC).
System wykrywania włamań IDS działa w trybie pasywnym out-of-band, monitorując kopię ruchu sieciowego przez zwierciadlany port przełącznika i generując alarmy bez ingerencji w transmisję. System zapobiegania włamaniom IPS działa w trybie aktywnym inline, znajdując się bezpośrednio na ścieżce ruchu i mogąc natychmiastowo blokować złośliwe pakiety, resetować połączenia lub odrzucać podejrzane datagramy. Analiza sygnaturowa polega na porównywaniu wzorców ruchu z bazą znanych sygnatur ataków, co jest skuteczne w wykrywaniu znanych zagrożeń, ale nie chroni przed nowymi, nieznanymi wcześniej atakami. Analiza anomalii buduje profil normalnego ruchu sieciowego i alarmuje przy odchyleniach od tego profilu, co umożliwia wykrywanie nowych typów ataków i nietypowych zachowań w sieci. Analiza stanu protokołu weryfikuje zgodność ruchu ze specyfikacjami RFC, wykrywając ataki wykorzystujące nieprawidłowe struktury pakietów lub naruszenia sekwencji protokołów.
IDS jest przydatny przede wszystkim w analizie forensycznej i audytach bezpieczeństwa, ponieważ dostarcza szczegółowych zapisów zdarzeń bez ryzyka blokowania legalnego ruchu. IPS z kolei jest niezbędny w środowiskach wymagających natychmiastowej reakcji na zagrożenia, na przykład w sieciach bankowych i centrach danych. Współczesne systemy IDS i IPS coraz częściej wykorzystują techniki uczenia maszynowego do wykrywania zaawansowanych i rozmytych wzorców ataków, które są trudne do uchwycenia przez tradycyjne sygnatury. Systemy hybrydowe łączące cechy IDS i IPS w jednym urządzeniu pozwalają na elastyczne dostosowanie trybu pracy do konkretnych potrzeb i polityki bezpieczeństwa organizacji. Skuteczność systemów IDS i IPS zależy w dużej mierze od regularności aktualizacji baz sygnatur oraz prawidłowego dostrojenia czułości detekcji do specyfiki chronionej sieci.
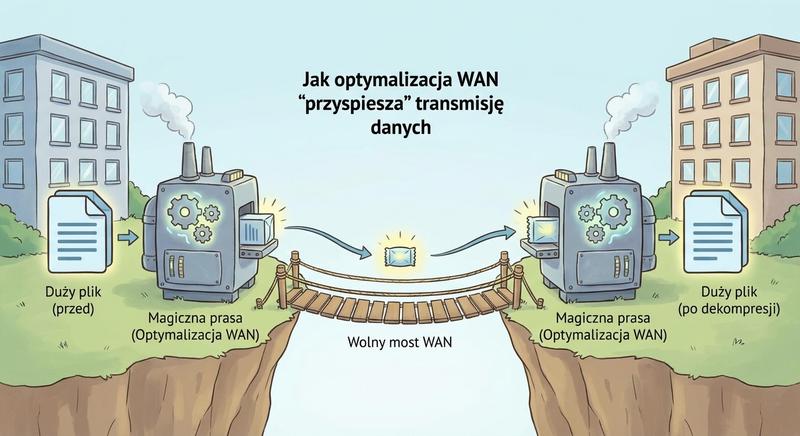
Optymalizacja WAN (WAN Optimization) to zestaw technik i urządzeń mających na celu poprawę wydajności aplikacji działających w rozległych sieciach WAN. Jest to szczególnie istotne w przypadku łączy o wysokim opóźnieniu (latency) i ograniczonej przepustowości.
Urządzenia optymalizujące WAN (np. Riverbed Steelhead, Cisco WAAS) stosują kilka technik: deduplikację danych (eliminacja przesyłania tych samych danych wielokrotnie – zasada „wyślij raz"), kompresję strumieniową, buforowanie aplikacji (application acceleration), optymalizację protokołów TCP (np. zwiększanie okna TCP, local TCP termination) oraz priorytetyzację ruchu (QoS). Współcześnie funkcje optymalizacji WAN często są zintegrowane z urządzeniami SD-WAN i NGFW, tworząc wielofunkcyjne platformy (branch-in-a-box) łączące routing, firewalling, proxy, WAN optimization i VPN.
Optymalizacja WAN to zestaw technik mających na celu poprawę wydajności aplikacji działających w sieciach rozległych o wysokim opóźnieniu i ograniczonej przepustowości. Deduplikacja danych eliminuje konieczność wielokrotnego przesyłania tych samych danych przez sieć WAN, wysyłając blok danych tylko raz i zastępując kolejne wystąpienia znacznikami referencyjnymi. Kompresja strumieniowa zmniejsza rozmiar przesyłanych danych poprzez algorytmy kompresji bezstratnej, co jest szczególnie skuteczne w przypadku ruchu tekstowego i nieskompresowanych plików. Optymalizacja protokołów TCP modyfikuje zachowanie stosu TCP, na przykład poprzez zwiększanie rozmiaru okna lub lokalne potwierdzanie segmentów, aby przeciwdziałać negatywnemu wpływowi dużego opóźnienia na przepustowość. Mechanizmy QoS priorytetyzują ruch krytyczny dla biznesu, taki jak VoIP czy aplikacje ERP, kosztem mniej ważnych transmisji, takich jak pobieranie plików czy aktualizacje systemowe.
Współczesne urządzenia SD-WAN integrują funkcje optymalizacji WAN bezpośrednio z routingiem i bezpieczeństwem, tworząc wielofunkcyjne platformy typu branch-in-a-box. Dzięki temu firmy mogą zastąpić kilka oddzielnych urządzeń w oddziałach jedną platformą łączącą routing, firewalling, proxy i optymalizację WAN. Urządzenia optymalizujące WAN stosują również buforowanie aplikacji, przechowując lokalnie często używane bloki danych i serwując je z pamięci podręcznej zamiast pobierać przez wolne łącze WAN. Technologia local TCP termination pozwala na potwierdzanie segmentów TCP lokalnie po każdej stronie łącza WAN, co przyspiesza transfer nawet przy znacznym opóźnieniu sieci rozległej. Wdrożenie optymalizacji WAN może znacząco poprawić czas odpowiedzi aplikacji i zmniejszyć wykorzystanie pasma, opłacając się szczególnie w firmach z wieloma oddziałami połączonymi kosztownymi łączami WAN.
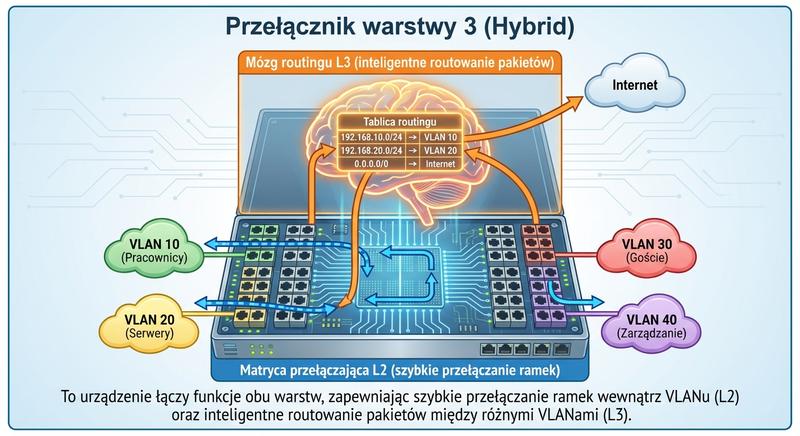
Przełącznik warstwy 3 (L3 Switch, multilayer switch) to urządzenie łączące w sobie funkcje przełącznika (switch) i routera. Potrafi podejmować decyzje zarówno na podstawie adresów MAC (L2), jak i adresów IP (L3), realizując routing między podsieciami z prędkością zbliżoną do przełączania.
Kluczową różnicą między L3 Switch a klasycznym routerem jest sposób przetwarzania pakietów. Routery korzystają głównie z routingu programowego (procesor CPU analizuje każdy pakiet), podczas gdy L3 Switch stosuje routing sprzętowy (ASIC – Application-Specific Integrated Circuit), co pozwala osiągać przepustowości rzędu wielu terabitów na sekundę. L3 Switch jest idealnym rozwiązaniem do szybkiego routingu w obrębie sieci lokalnych (inter-VLAN routing), ale nie posiada zaawansowanych funkcji routerów brzegowych (jak BGP, NAT, VPN, zaawansowane ACL). W praktyce L3 Switch świetnie sprawdza się w rdzeniu sieci LAN (campus core) lub jako przełącznik dystrybucyjny.
Przełącznik warstwy trzeciej, zwany również przełącznikiem wielowarstwowym, łączy w jednym urządzeniu funkcje przełącznika Ethernet i routera IP, umożliwiając zarówno przełączanie w warstwie drugiej, jak i routing w warstwie trzeciej. Kluczową różnicą między L3 Switch a klasycznym routerem jest sposób przetwarzania pakietów router korzysta głównie z routingu programowego, w którym procesor CPU analizuje każdy pakiet, podczas gdy L3 Switch stosuje routing sprzętowy w układach ASIC. Dzięki zastosowaniu układów ASIC przełącznik L3 może osiągać przepustowości rzędu wielu terabitów na sekundę przy bardzo niskich opóźnieniach, co jest nieosiągalne dla tradycyjnych routerów programowych. L3 Switch jest idealnym rozwiązaniem do szybkiego routingu między sieciami VLAN w obrębie sieci lokalnych, gdzie wymagana jest wysoka wydajność przy stosunkowo prostej konfiguracji. W odróżnieniu od pełnoprawnych routerów brzegowych, L3 Switch nie oferuje zaawansowanych protokołów routingu, takich jak BGP, ani funkcji translacji adresów NAT czy koncentracji VPN.
W hierarchicznej architekturze sieci przełączniki L3 sprawdzają się doskonale w warstwie dystrybucyjnej i rdzeniowej, gdzie kluczowe znaczenie ma szybkie przekazywanie pakietów między podsieciami. Konfiguracja routingu między VLAN na przełączniku L3 polega na utworzeniu interfejsów wirtualnych SVI dla każdej sieci VLAN i przypisaniu im adresów IP z odpowiednich podsieci. Przełączniki wielowarstwowe potrafią również obsługiwać listy kontroli dostępu na poziomie warstwy trzeciej i czwartej, co pozwala na podstawową filtrację ruchu między sieciami VLAN. W praktyce L3 Switch jest często stosowany jako szkielet sieci kampusowych i centrów danych, gdzie musi przetwarzać ogromne ilości ruchu z minimalnymi opóźnieniami. Mimo że L3 Switch nie zastąpi pełnoprawnego routera na styku sieci z Internetem, stanowi niezbędny element nowoczesnych sieci lokalnych wymagających szybkiego routingu między wieloma podsieciami.
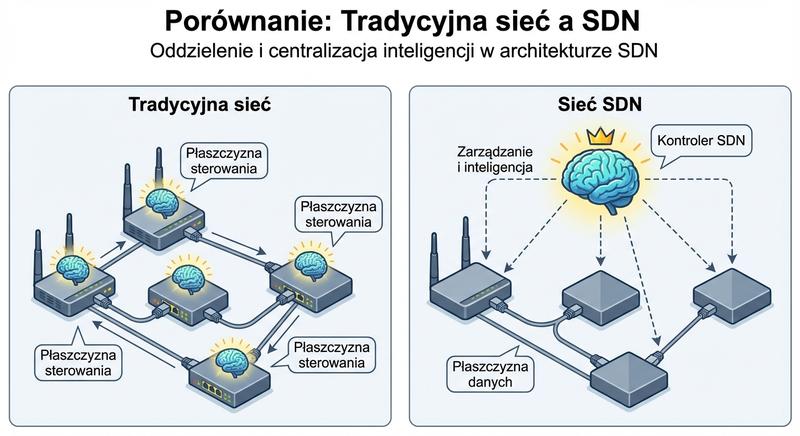
Software-Defined Networking (SDN) to paradygmat sieciowy, który oddziela płaszczyznę sterowania (control plane) od płaszczyzny danych (data plane). Dzięki temu zarządzanie siecią staje się programowalne, scentralizowane i elastyczne, co stanowi rewolucję w porównaniu z tradycyjnymi sieciami rozproszonymi.
W modelu SDN mamy trzy warstwy: warstwę aplikacji (aplikacje sieciowe definiujące polityki), warstwę sterowania (scentralizowany kontroler SDN, np. OpenDaylight, ONOS, Ryu) oraz warstwę infrastruktury (przełączniki fizyczne/wirtualne). Komunikacja między kontrolerem a przełącznikami odbywa się za pomocą protokołu OpenFlow lub, w nowszych rozwiązaniach, poprzez interfejsy programistyczne (API) takie jak P4 Runtime czy gRPC. SDN umożliwia automatyzację konfiguracji, szybkie wdrażanie nowych usług sieciowych oraz centralny wgląd w ruch. SDN jest fundamentem dla Network Virtualization (NFV) i chmur obliczeniowych.
Sieci definiowane programowo SDN to paradygmat sieciowy, który oddziela płaszczyznę sterowania od płaszczyzny danych, umożliwiając scentralizowane i programowalne zarządzanie infrastrukturą sieciową. W modelu SDN wyróżnia się trzy warstwy warstwę aplikacji zawierającą programy definiujące polityki sieciowe, warstwę sterowania ze scentralizowanym kontrolerem SDN oraz warstwę infrastruktury złożoną z fizycznych lub wirtualnych przełączników. Komunikacja między kontrolerem a przełącznikami odbywa się za pomocą protokołu OpenFlow, który definiuje sposób instalowania reguł przekazywania pakietów w urządzeniach sieciowych. Nowsze podejścia, takie jak P4 i gRPC, umożliwiają jeszcze większą elastyczność poprzez programowalną definicję sposobu przetwarzania pakietów bezpośrednio w układach ASIC. SDN umożliwia automatyzację konfiguracji sieci, szybkie wdrażanie nowych usług oraz centralny wgląd w cały ruch przechodzący przez infrastrukturę, co znacząco redukuje nakład pracy administracyjnej.
Kontroler SDN pełni rolę mózgu sieci, mając pełny obraz topologii i mogąc dynamicznie dostosowywać reguły przepływu do zmieniających się warunków i wymagań aplikacji. Popularne kontrolery SDN to OpenDaylight, ONOS oraz Ryu, każdy z nich oferujący różne interfejsy programistyczne i wsparcie dla protokołów południowych i północnych. Protokół OpenFlow definiuje strukturę przepływów, które mogą być dopasowywane na podstawie dwunastu różnych pól nagłówka, od adresów MAC i IP po numery portów TCP. SDN stanowi fundament dla wirtualizacji funkcji sieciowych NFV i jest szeroko stosowany w centrach danych oraz sieciach operatorów telekomunikacyjnych do dynamicznego zarządzania zasobami. Dzięki separacji płaszczyzn SDN umożliwia wprowadzanie nowych funkcji sieciowych bez konieczności wymiany sprzętu, ponieważ zmiany konfiguracji są wprowadzane centralnie w kontrolerze.
Współczesne sieci charakteryzują się zjawiskiem zacierania się tradycyjnych granic między poszczególnymi typami urządzeń. Coraz częściej zamiast osobnych urządzeń dla każdej funkcji, spotykamy platformy wielofunkcyjne łączące wiele ról.
Przykładem jest UTM (Unified Threat Management) – urządzenie łączące firewalla, IPS, antywirus, filtrowanie URL, VPN, a często również routing i przełączanie. Innym przykładem jest platforma SD-WAN, która integruje routing, optymalizację WAN, VPN i firewalling. Również w chmurze obliczeniowej funkcje sieciowe są wirtualizowane (Virtual Network Functions – VNF) i uruchamiane na standardowych serwerach. To sprawia, że inżynier sieci musi dziś rozumieć nie tylko poszczególne urządzenia, ale także sposób ich integracji i wzajemnego oddziaływania w złożonych, wielofunkcyjnych platformach.
Współczesne sieci charakteryzują się zjawiskiem zacierania się tradycyjnych granic między poszczególnymi typami urządzeń sieciowych, co prowadzi do powstawania wielofunkcyjnych platform integrujących wiele ról. Przykładem takiego trendu jest UTM, czyli Unified Threat Management, które łączy w jednym urządzeniu firewall, IPS, antywirus, filtrowanie URL, VPN, a często także routing i przełączanie. Platformy SD-WAN integrują routing, optymalizację WAN, VPN i firewalling w jednym, centralnie zarządzanym rozwiązaniu, zastępując kilka osobnych urządzeń w oddziałach firm. W chmurze obliczeniowej tradycyjne funkcje sieciowe są wirtualizowane jako VNF i uruchamiane na standardowych serwerach, co pozwala na elastyczne skalowanie i szybkie wdrażanie nowych usług. To zacieranie granic sprawia, że współczesny inżynier sieci musi rozumieć nie tylko poszczególne urządzenia, ale przede wszystkim sposób ich integracji i wzajemnego oddziaływania w złożonych platformach.
Koncepcja branch-in-a-box, czyli jednego urządzenia w oddziale firmy obsługującego wszystkie funkcje sieciowe, zyskuje na popularności ze względu na niższe koszty i prostsze zarządzanie. Wirtualne funkcje sieciowe VNF, takie jak wirtualne routery czy zapory, mogą być uruchamiane na standardowym sprzęcie serwerowym w środowiskach chmurowych lub lokalnych centrach danych. Producenci urządzeń sieciowych coraz częściej oferują licencjonowanie oparte na subskrypcji, które umożliwia odblokowywanie dodatkowych funkcji programowo bez konieczności wymiany sprzętu. Mikrosegmentacja i polityki Zero Trust wymuszają podejście wielowarstwowe, w którym bezpieczeństwo jest wbudowane we wszystkie elementy infrastruktury, a nie tylko w dedykowane urządzenia. Przyszłość sieci zmierza w kierunku całkowicie programowalnych platform, gdzie granice między urządzeniami są definiowane przez oprogramowanie, a nie przez sprzętowe ograniczenia.
Aby zrozumieć, jak współdziałają wszystkie omówione urządzenia, prześledźmy drogę zapytania sieciowego od przeglądarki użytkownika do serwera internetowego i z powrotem.
- Warstwa aplikacji (Klient): Użytkownik wpisuje adres URL w przeglądarce. System operacyjny sprawdza, czy adres IP jest w lokalnej pamięci podręcznej DNS. Jeśli nie, wysyła zapytanie DNS (UDP, port 53).
- DNS Resolution: Zapytanie DNS przechodzi przez switch, router i ewentualnie proxy/firewall. Serwer DNS zwraca adres IP docelowy (np. 93.184.216.34).
- Połączenie TCP (L4): Przeglądarka nawiązuje połączenie TCP z docelowym serwerem (three-way handshake). Połączenie może być przechwycone przez stateful firewall i load balancer.
- Negocjacja TLS (L5/L6): Jeśli używany jest HTTPS, następuje uzgadnianie TLS. Load balancer może wykonać SSL offloading.
- Żądanie HTTP (L7): Przeglądarka wysyła żądanie GET. Proxy lub WAF analizuje treść. Load Balancer L7 przekierowuje do odpowiedniego serwera backendu.
- Odpowiedź: Serwer przetwarza żądanie, odsyła odpowiedź, która wraca tą samą drogą do klienta.
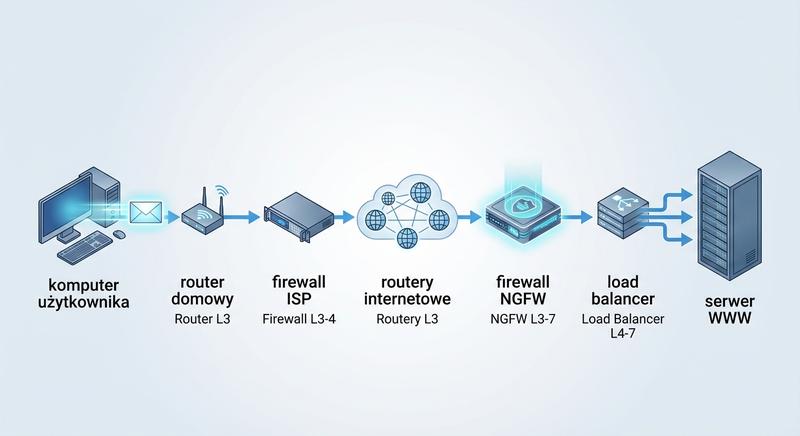
Cykl życia zapytania sieciowego rozpoczyna się od wpisania adresu URL w przeglądarce, po czym system operacyjny sprawdza lokalną pamięć podręczną DNS i w razie potrzeby wysyła zapytanie DNS przez sieć lokalną. Zapytanie DNS przechodzi przez przełącznik warstwy drugiej, router domyślny i ewentualnie przez serwer proxy lub firewall, aż dotrze do autorytatywnego serwera DNS, który zwraca adres IP docelowej domeny. Po uzyskaniu adresu IP przeglądarka nawiązuje połączenie TCP z serwerem docelowym poprzez trójfazowe uzgadnianie SYN, SYN-ACK i ACK, które może być monitorowane przez zaporę stanową. W przypadku protokołu HTTPS po nawiązaniu połączenia TCP następuje negocjacja TLS, podczas której uzgadniane są parametry szyfrowania i wymieniane certyfikaty, a load balancer może wykonać SSL offloading. Następnie przeglądarka wysyła żądanie HTTP GET, które jest analizowane przez proxy lub zapora aplikacyjną WAF, po czym load balancer L7 przekierowuje je do odpowiedniego serwera backendu na podstawie treści żądania.
Serwer backendu przetwarza żądanie, generuje odpowiedź i odsyła ją do klienta tą samą drogą przez load balancer, firewall i przełączniki sieciowe. Podczas całej tej podróży każde urządzenie pośredniczące odgrywa swoją rolę przełącznik przekazuje ramki na podstawie adresów MAC, router kieruje pakiety między sieciami, a zapora weryfikuje zgodność ruchu z politykami bezpieczeństwa. Load balancer może zmodyfikować trasę odpowiedzi, jeśli działa w trybie DSR, w którym serwer odpowiada bezpośrednio klientowi z pominięciem urządzenia równoważącego. Zapora stanowa aktualizuje swoją tablicę stanów połączeń przy każdym pakiecie, upewniając się, że należy on do prawidłowo ustanowionej sesji. Cały proces od wpisania adresu URL do wyświetlenia strony trwa zazwyczaj ułamek sekundy, co jest możliwe dzięki wydajnemu współdziałaniu wszystkich urządzeń na każdym etapie transmisji.
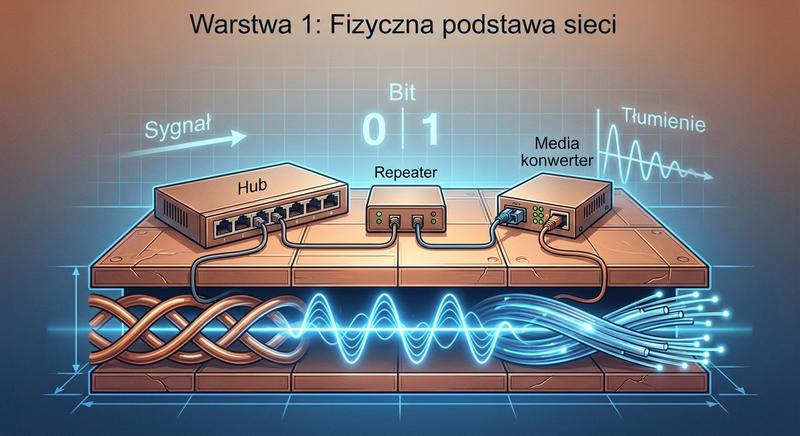
Warstwa fizyczna (L1) to fundament każdej sieci. Odpowiada za przesyłanie surowych bitów przez medium transmisyjne. W trakcie kursu omówiliśmy:
Kable koncentryczne, skrętkę (UTP/STP), światłowody jednomodowe i wielomodowe, a także standardy takie jak 10BASE5, 10BASE2, 100BASE-TX, 1000BASE-T. Poznaliśmy urządzenia warstwy 1: repeatery (wzmacniacze sygnału), koncentratory (huby) oraz media konwertery (transceivery). Kluczowymi pojęciami są: tłumienie sygnału (attenuation), przesłuchy (crosstalk), szybkość transmisji (bitrate), kodowanie linii (np. Manchester, 4B/5B, NRZ) oraz maksymalne długości segmentów. Warstwa 1 nie dokonuje żadnych decyzji logicznych – po prostu przenosi sygnał.
Warstwa fizyczna stanowi fundament każdej sieci komputerowej i odpowiada za przesyłanie surowych bitów przez medium transmisyjne między urządzeniami nadawcy i odbiorcy. W trakcie kursu omówiliśmy różne rodzaje mediów transmisyjnych, w tym kable koncentryczne, skrętkę UTP i STP oraz światłowody jednomodowe i wielomodowe, każdy o innych właściwościach i zastosowaniach. Poznaliśmy urządzenia warstwy fizycznej repeatery regenerujące sygnał wzmacniający transmisję na dłuższych dystansach, koncentratory łączące wiele urządzeń w topologii gwiazdy oraz media konwertery umożliwiające łączenie różnych typów mediów. Kluczowymi pojęciami są tłumienie sygnału, które ogranicza maksymalną długość segmentu sieciowego oraz przesłuchy elektromagnetyczne zakłócające transmisję między sąsiednimi parami przewodów. Szybkość transmisji wyrażana w bitach na sekundę oraz metody kodowania linii, takie jak Manchester, 4B5B i NRZ, decydują o efektywności wykorzystania dostępnego pasma medium transmisyjnego.
Warstwa fizyczna nie podejmuje żadnych decyzji logicznych i nie analizuje przesyłanych danych, jej jedynym zadaniem jest przeniesienie sygnału z punktu A do punktu B w jak najwierniejszej postaci. Standardy takie jak 10BASE5, 10BASE2, 100BASE-TX i 1000BASE-T definiują konkretne parametry transmisji, w tym maksymalne długości segmentów, typy złączy i metody kodowania. W światłowodach rozróżniamy transmisję jednomodową, w której światło biegnie prosto przez rdzeń, oraz wielomodową, gdzie promienie odbijają się od ścianek rdzenia, co wpływa na maksymalną odległość i przepustowość. Okablowanie strukturalne w nowoczesnych budynkach opiera się na skrętce kategorii 5e, 6 lub 6a, które różnią się pasmem przenoszenia i odpornością na zakłócenia. Zrozumienie ograniczeń i właściwości warstwy fizycznej jest niezbędne przy projektowaniu niezawodnych i wydajnych sieci, ponieważ problemy na tym poziomie często objawiają się w wyższych warstwach w postaci błędów transmisji i wolnego działania aplikacji.
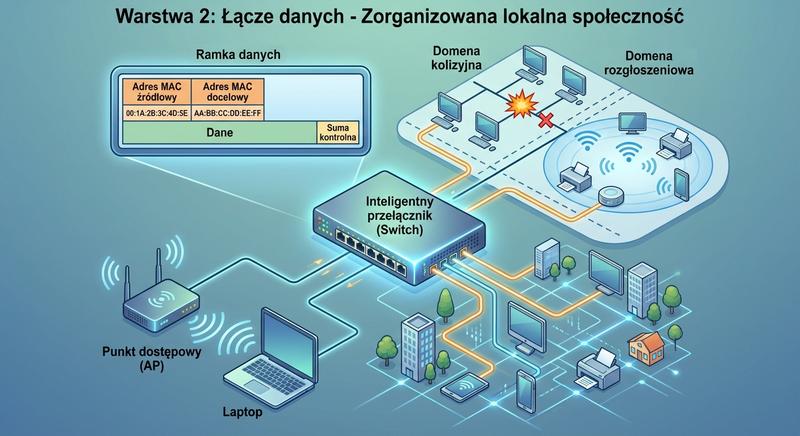
Warstwa łącza danych (L2) odpowiada za niezawodną komunikację między sąsiednimi urządzeniami w tej samej sieci lokalnej. Najważniejszym protokołem L2 jest Ethernet (IEEE 802.3).
Omówiliśmy szczegółowo adresację MAC (48-bitową, OUI, unicast/multicast/broadcast), budowę ramki Ethernet (preambuła, SFD, nagłówek z adresami MAC, EtherType, dane, FCS/trailer), protokół CSMA/CD (Carrier Sense Multiple Access with Collision Detection) oraz domeny kolizyjne. Poznaliśmy przełączniki L2 (switche) – ich działanie oparte na tablicy adresów MAC (MAC address table/CAM table), metody przełączania (store-and-forward, cut-through, fragment-free), protokół STP/RSTP (zapobieganie pętlom) oraz VLAN (802.1Q) i tryby portów (access, trunk). Most (bridge) jako prekursor przełącznika został wspomniany w kontekście segmentacji domen kolizyjnych.
Warstwa druga modelu OSI, czyli warstwa lącza danych, stanowi pomost między fizycznym przesyłaniem bitów a logiczną komunikacją między urządzeniami w sieci lokalnej. To właśnie na tej warstwie adresy MAC pozwalają jednoznacznie identyfikować interfejsy sieciowe w obrębie jednego segmentu sieci. Ramka Ethernet, będąca jednostką PDU warstwy drugiej, zawiera nie tylko dane użytkownika, ale także istotne informacje sterujące, takie jak adresy źródłowy i docelowy MAC oraz pole EtherType. Mechanizm CSMA/CD, choć dziś wyparty przez przełączniki i pełny dupleks, odegrał kluczową rolę w rozwoju sieci Ethernet opartych na koncentratorach. Przełączniki warstwy drugiej uczą się na podstawie nadawców ramek, budując tablicę adresów MAC, która umożliwia podejmowanie świadomych decyzji o przekazywaniu ramek tylko do odpowiedniego portu.
Protokół STP oraz jego szybszy następca RSTP zapobiegają powstawaniu pętli w sieciach z nadmiarowymi połączeniami, co mogłoby doprowadzić do przeciążenia sieci przez niekończące się krążenie ramek broadcastowych. Wirtualne sieci lokalne VLAN, definiowane w standardzie 802.1Q, umożliwiają logiczne dzielenie jednej fizycznej infrastruktury przełącznika na odizolowane od siebie domeny rozgłoszeniowe. Każdy VLAN stanowi osobną sieć warstwy drugiej, a komunikacja między nimi wymaga już udziału urządzenia warstwy trzeciej, takiego jak router lub przełącznik wielowarstwowy. Na portach dostępowych hosty końcowe są przyporządkowane do jednego VLAN-u, natomiast porty trunk przenoszą ruch wielu VLAN-ów między przełącznikami, dodając znacznik 802.1q. Zrozumienie tych mechanizmów jest niezbędne przy projektowaniu wydajnych i bezpiecznych sieci lokalnych w firmach i instytucjach.
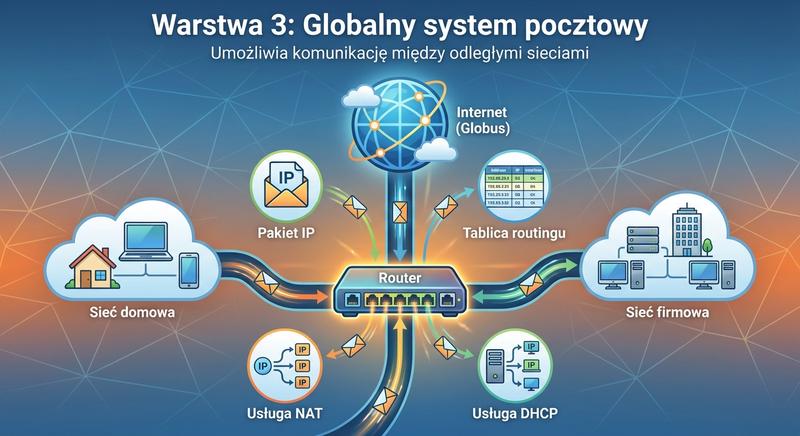
Warstwa sieciowa (L3) odpowiada za adresację logiczną i routowanie pakietów między różnymi sieciami. Podstawowym protokołem L3 w Internecie jest IP (IPv4 i IPv6).
Poznaliśmy adresację IPv4 (klasy A/B/C, CIDR, maski podsieci, adresy publiczne i prywatne), budowę pakietu IP (nagłówek z polami: version, IHL, ToS/DSCP, TTL, protocol, source/destination IP, checksum), protokół ARP (rozwiązywanie adresów IP na MAC), ICMP (ping, traceroute), a także IPv6 (128-bitowe adresy, notacja heksadecymalna, NDP w miejsce ARP). Omówiliśmy routery – ich działanie (lookup w tablicy routingu, routing statyczny i dynamiczny), protokoły routingu (RIP, OSPF, EIGRP, BGP) oraz metryki. Przedstawiliśmy również przełącznik L3 (multilayer switch) jako przykład urządzenia wielowarstwowego łączącego funkcje L2 i L3.
Warstwa sieciowa umożliwia komunikację między urządzeniami należącymi do różnych sieci logicznych, co jest podstawą działania globalnej sieci Internet. Adresacja IPv4 opiera się na 32-bitowych adresach zapisywanych w notacji kropkowo-dziesiętnej, a wraz z maską podsieci pozwala określić przynależność hosta do konkretnej podsieci. Budowa pakietu IP zawiera między innymi pole TTL zapobiegające krążeniu pakietów w pętli, protokół identyfikujący wyższy protokół transportowy oraz sumę kontrolną nagłówka. Protokół ARP pełni niezwykle istotną funkcję tłumaczenia adresów warstwy trzeciej na adresy warstwy drugiej, bez czego komunikacja w sieci Ethernet nie mogłaby zaistnieć. ICMP z kolei dostarcza narzędzi diagnostycznych takich jak ping i traceroute, które pozwalają inżynierom badać dostępność i trasę pakietów w sieci.
Routery, jako podstawowe urządzenia warstwy trzeciej, podejmują decyzje o przekazywaniu pakietów na podstawie tablicy routingu, która może być wypełniana statycznie lub dynamicznie przez protokoły routingu. Protokół RIP opiera się na liczniku przeskoków i sprawdza się jedynie w małych sieciach, podczas gdy OSPF buduje topologię całej sieci przy użyciu algorytmu najkrótszej ścieżki. EIGRP, będący rozwiązaniem Cisco, łączy cechy protokołów wektora odległości i stanu łącza, oferując szybką zbieżność w sieciach jednolitego producenta. BGP z kolei jest protokołem używanym między systemami autonomicznymi w rdzeniu Internetu i odpowiada za wymianę informacji o dostępności całych bloków adresowych. Przełącznik wielowarstwowy L3 łączy w sobie szybkość przełączania sprzętowego z możliwością routowania między sieciami VLAN, co czyni go idealnym rozwiązaniem dla szkieletów sieci korporacyjnych.
Wyższe warstwy (L4-L7) to domena aplikacji, bezpieczeństwa i inteligentnego zarządzania ruchem. To właśnie te warstwy decydują o tym, jakie usługi są dostępne dla użytkownika końcowego.
Omówiliśmy warstwę transportową (L4) z protokołami TCP (niezawodny, połączeniowy, kontrola przepływu, okno przesuwne, three-way handshake) i UDP (szybki, bezpołączeniowy, bez retransmisji). Wprowadziliśmy pojęcie portów (źródłowy, docelowy) i gniazd (socket = IP:port). Na poziomie warstwy aplikacji (L7) poznaliśmy protokoły HTTP/HTTPS, DNS, DHCP, SMTP, FTP. Omówiliśmy szczegółowo urządzenia operujące na tych warstwach: firewalle (stateless, stateful, NGFW), WAF, serwery proxy (forward, reverse, transparent), load balancery (L4, L7), koncentratory VPN oraz systemy IDS/IPS.
Warstwy od czwartej do siódmej modelu OSI obejmują funkcje związane z transportem danych między aplikacjami oraz samymi aplikacjami sieciowymi. Warstwa transportowa z protokołem TCP zapewnia niezawodne połączenie poprzez trójfazowe uzgadnianie, numerowanie segmentów, mechanizm potwierdzeń oraz kontrolę przepływu i przeciążeń. UDP z kolei oferuje szybką transmisję bez gwarancji dostarczenia, idealną dla strumieniowego wideo, gier sieciowych i zapytań DNS. Porty TCP i UDP wraz z adresami IP tworzą gniazda sieciowe, które jednoznacznie identyfikują każde połączenie w sieci. Warstwa aplikacji udostępnia protokoły, z których korzystają bezpośrednio programy użytkownika, takie jak HTTP dla stron internetowych, DNS dla tłumaczenia nazw domenowych oraz SMTP dla poczty elektronicznej.
Bezpieczeństwo na wyższych warstwach zapewniają wyspecjalizowane urządzenia, które analizują ruch w kontekście konkretnych aplikacji i protokołów. Zapory sieciowe nowej generacji NGFW łączą inspekcję stanową z kontrolą aplikacji i systemem zapobiegania włamaniom, oferując kompleksową ochronę przed złożonymi zagrożeniami. Zapory aplikacyjne WAF chronią serwisy internetowe przed atakami takimi jak wstrzykiwanie kodu SQL czy podatność XSS, analizując treść żądań HTTP. Serwery proxy buforują często odwiedzane zasoby i filtrują niepożądane treści, a load balancery dystrybuują ruch na wiele serwerów, zapewniając skalowalność i niezawodność usług. Koncentratory VPN umożliwiają bezpieczne łączenie oddzielonych geograficznie sieci oraz zdalny dostęp pracowników do zasobów firmowych przez publiczny Internet.
Po przejściu przez wszystkie warstwy modelu OSI i różne typy urządzeń, kluczowe staje się holistyczne spojrzenie na sieć jako na integralny system. Żadna warstwa nie działa w izolacji.
Holistyczne podejście oznacza rozumienie, jak decyzje podjęte na jednej warstwie wpływają na pozostałe. Na przykład: konfiguracja VLAN (L2) ma wpływ na routing (L3); polityki firewalla (L3-L7) mogą blokować ruch, który działa poprawnie na niższych warstwach; load balancing (L4/L7) zmienia sposób, w jaki serwery widzą ruch (asymetryczne routowanie, potrzeba session persistence). Współczesny inżynier sieci musi myśleć w kategoriach end-to-end, biorąc pod uwagę całą ścieżkę pakietu od źródła do celu, ze wszystkimi urządzeniami pośrednimi, ich konfiguracją i wzajemnymi zależnościami. To właśnie ta umiejętność odróżnia zaawansowanego administratora od początkującego technika.
Holistyczne spojrzenie na sieć wymaga zrozumienia, że poszczególne warstwy modelu OSI nie działają w izolacji, lecz tworzą wzajemnie powiązany i współzależny system. Każda decyzja konfiguracyjna podjęta na jednej warstwie może mieć bezpośredni lub pośredni wpływ na działanie warstw sąsiednich i odległych, co często prowadzi do nieoczekiwanych skutków ubocznych. Na przykład dodanie nowej sieci VLAN w warstwie drugiej wymaga skonfigurowania routingu między VLAN w warstwie trzeciej oraz ewentualnego dostosowania polityk zapory sieciowej w warstwach wyższych. Firewall może blokować ruch, który na poziomie warstwy drugiej i trzeciej wydaje się poprawnie skonfigurowany, jeśli reguły filtrujące nie uwzględniają konkretnych portów czy protokołów. Podobnie load balancer może zmienić przepływ ruchu w sposób powodujący asymetryczne routowanie, co z kolei może zostać zinterpretowane przez zapory stanowe jako próba ataku.
Podejście end-to-end oznacza analizę każdego zapytania sieciowego na całej jego drodze od źródła do celu, z uwzględnieniem wszystkich urządzeń pośredniczących. Praktycznym przykładem jest sytuacja, w której poprawnie działające połączenie warstwy drugiej i trzeciej nie przekłada się na działanie aplikacji z powodu reguł firewalla blokujących konkretne protokoły warstwy siódmej. Współczesne środowiska sieciowe są tak złożone, że inżynier musi umieć myśleć wielowarstwowo i przewidywać kaskadowe skutki zmian konfiguracyjnych. Umiejętność ta jest szczególnie cenna przy migracjach sieci, wdrażaniu nowych usług oraz przy rozwiązywaniu problemów, gdy objawy występują na innej warstwie niż pierwotna przyczyna. Dlatego tak ważne jest systematyczne poznawanie wszystkich warstw modelu referencyjnego zamiast skupiania się tylko na wybranej specjalizacji.
Sieci komputerowe to dziedzina, która nieustannie ewoluuje. Oto kluczowe kierunki rozwoju, którymi warto się zainteresować po ukończeniu tego kursu:
- Network Automation & DevOps: Narzędzia takie jak Ansible, Terraform, NAPALM, Python (biblioteki netmiko, napalm, pyATS) pozwalają na automatyzację konfiguracji i zarządzania sieciami.
- Cloud Networking: AWS, Azure, Google Cloud – sieci w chmurze (VPC, Security Groups, Transit Gateway, Cloud WAN, Virtual Private Cloud).
- SD-WAN: Cisco Viptela, VMware Velocloud, Fortinet SD-WAN – inteligentne zarządzanie łączami WAN z centralną orkiestracją.
- Network Security (Zero Trust): Architektura Zero Trust (NIST 800-207), mikrosegmentacja, SASE (Secure Access Service Edge), ZTNA (Zero Trust Network Access).
- Observability i AIOps: Cisco ThousandEyes, Kentik, ExtraHop – monitoring sieci wspomagany sztuczną inteligencją.
Dziedzina sieci komputerowych rozwija się w zawrotnym tempie, a znajomość tradycyjnych technologii musi być uzupełniana o nowe paradygmaty i narzędzia. Automatyzacja sieci za pomocą narzędzi takich jak Ansible i Terraform pozwala na konfigurację dziesiątek czy setek urządzeń za pomocą jednego skryptu, co znacząco redukuje ryzyko błędu ludzkiego i przyspiesza wdrażanie zmian. Chmura obliczeniowa wprowadziła nowe modele sieciowe, w których funkcje takie jak firewalle, routery i load balancery są dostarczane jako usługi programowalne w środowiskach AWS, Azure i Google Cloud. Sieci definiowane programowo SDN oddzielają płaszczyznę sterowania od danych, umożliwiając centralne zarządzanie politykami sieciowymi przez interfejs programistyczny. Technologia SD-WAN zastępuje tradycyjne routery WAN inteligentnym oprogramowaniem, które dynamicznie wybiera najlepszą ścieżkę dla ruchu w zależności od warunków panujących na łączach.
Bezpieczeństwo sieci ewoluuje w stronę architektury Zero Trust, która zakłada, że żadne urządzenie ani użytkownik nie jest domyślnie zaufany, nawet jeśli znajduje się wewnątrz sieci firmowej. Model SASE łączy funkcje sieciowe i bezpieczeństwa w jednej chmurowej usłudze, dostarczanej z brzegu sieci w zależności od lokalizacji użytkownika. AIOps wykorzystuje sztuczną inteligencję i uczenie maszynowe do analizy ogromnych ilości danych sieciowych, umożliwiając przewidywanie awarii i automatyczne rozwiązywanie problemów. Coraz większe znaczenie mają również umiejętności programistyczne, ponieważ nowoczesne środowiska sieciowe wymagają pisania skryptów w języku Python oraz znajomości interfejsów API REST. Inżynier sieci przyszłości musi łączyć wiedzę o tradycyjnych protokołach z umiejętnością programowania i rozumieniem architektur chmurowych.
Najważniejsze pojęcia z dziś:
- Firewall, NGFW, WAF: Urządzenia bezpieczeństwa filtrujące ruch od L3 do L7. NGFW dodaje DPI, IPS i kontrolę aplikacji. WAF chroni aplikacje webowe przed atakami L7.
- Serwer Proxy: Pośrednik w komunikacji HTTP/HTTPS, oferujący caching, filtrowanie, anonimizację.
- Load Balancer: Dystrybucja ruchu na wiele serwerów (L4/L7). Kluczowe algorytmy: round robin, least connections, source hash.
- SSL Offloading: Odciążanie serwerów z szyfrowania TLS na load balancerze.
- VPN Concentrator: Bezpieczne tunele dla zdalnego dostępu i łączenia sieci.
- IDS/IPS: Monitorowanie i blokowanie ataków (sygnatury, anomalie).
- L3 Switch: Przełącznik z funkcją routingu sprzętowego (inter-VLAN routing).
- SDN: Oddzielenie control plane od data plane, centralny kontroler, OpenFlow.
Piąta część kursu poświęcona była urządzeniom działającym w wyższych warstwach modelu OSI oraz urządzeniom wielowarstwowym, które łączą funkcje wielu warstw w jednym sprzęcie. Zapora sieciowa w swojej najprostszej postaci filtruje pakiety na podstawie adresów i portów, ale zaawansowane urządzenia NGFW sięgają do warstwy aplikacji, analizując treść przesyłanych danych. Zapora aplikacyjna WAF specjalizuje się w ochronie serwisów internetowych przed atakami na poziomie protokołu HTTP, takimi jak wstrzykiwanie kodu SQL czy fałszowanie żądań międzywitrynowych. Serwer proxy działa jako pośrednik między klientem a serwerem docelowym, umożliwiając buforowanie, filtrowanie treści i ukrywanie topologii sieci wewnętrznej. Load balancer rozdziela ruch na wiele serwerów zaplecza według wybranego algorytmu, co zapewnia wysoką dostępność i optymalne wykorzystanie zasobów obliczeniowych.
Odciążanie SSL na load balancerze przenosi kosztowne obliczeniowo operacje kryptograficzne z serwerów aplikacyjnych na dedykowane urządzenie, które centralnie zarządza certyfikatami. Koncentrator VPN umożliwia budowanie bezpiecznych tuneli przez publiczną sieć, co jest niezbędne dla łączenia oddziałów firmy i zapewnienia zdalnego dostępu pracownikom. Systemy IDS i IPS monitorują ruch w poszukiwaniu śladów ataków, przy czym IPS może aktywnie blokować zagrożenia w czasie rzeczywistym. Przełącznik warstwy trzeciej łączy zalety przełącznika i routera, oferując sprzętowe routowanie między sieciami VLAN z prędkością zbliżoną do przełączania w warstwie drugiej. Sieci definiowane programowo stanowią przyszłość zarządzania infrastrukturą, oddzielając logikę sterowania od sprzętu i umożliwiając automatyzację konfiguracji przez scentralizowany kontroler.
Po ukończeniu tego kursu powinieneś posiadać solidne podstawy teoretyczne i praktyczne. Oto zestaw umiejętności, które są niezbędne dla każdego inżyniera sieci:
- Znajomość modeli referencyjnych: OSI (7 warstw) i TCP/IP – rozumienie enkapsulacji, dekapsulacji i funkcji każdej warstwy.
- Adresacja IP i podsieci: Biegłe obliczanie masek, adresów sieci, rozgłoszeniowych, VLSM, CIDR.
- Konfiguracja urządzeń sieciowych: Praktyczna umiejętność konfiguracji switchy i routerów (Cisco IOS, VLAN, STP, routing statyczny, OSPF, ACL, NAT).
- Diagnostyka i rozwiązywanie problemów: ping, traceroute, tcpdump, Wireshark, analiza logów, interpretacja outputów show commands.
- Bezpieczeństwo sieci: Projektowanie firewalli, zarządzanie regułami ACL, VPN, segmentacja sieci.
- Dokumentacja: Tworzenie schematów sieciowych (diagramy L2/L3), dokumentacja IPAM, procedury zmian.
Inżynier sieci musi przede wszystkim biegle posługiwać się modelami OSI i TCP/IP, ponieważ stanowią one uniwersalny język opisu komunikacji sieciowej i są podstawą do zrozumienia enkapsulacji danych. Adresacja IP i umiejętność obliczania podsieci to absolutna podstawa, bez której nie sposób poprawnie zaprojektować ani skonfigurować żadnej sieci komputerowej. Praktyczna konfiguracja urządzeń Cisco IOS, obejmująca tworzenie sieci VLAN, protokołu STP, routingu statycznego i dynamicznego, list kontroli dostępu oraz translacji adresów NAT, jest umiejętnością poszukiwaną na rynku pracy. Narzędzia diagnostyczne takie jak ping i traceroute pozwalają szybko lokalizować problemy z łącznością, ale dopiero umiejętność interpretacji wyników i łączenia ich z wiedzą o protokołach daje pełny obraz sytuacji. Wireshark jako analizator protokołów umożliwia dogłębne badanie poszczególnych pakietów i jest niezastąpiony przy rozwiązywaniu złożonych problemów sieciowych.
Bezpieczeństwo sieci to kolejny kluczowy obszar, w którym inżynier musi swobodnie poruszać się między regułami firewalla, listami ACL, sieciami VPN i segmentacją VLAN. Umiejętność tworzenia przejrzystej i aktualnej dokumentacji technicznej, obejmującej schematy logiczne i fizyczne sieci oraz rejestry adresacji IP, jest często niedoceniana, a stanowi podstawę sprawnego zarządzania infrastrukturą. Znajomość protokołów routingu dynamicznego, szczególnie OSPF w przypadku sieci wewnętrznych oraz BGP w przypadku łączenia z Internetem, pozwala projektować skalowalne i odporne na awarie topologie. Automatyzacja konfiguracji za pomocą skryptów i narzędzi takich jak Ansible staje się standardem w nowoczesnych środowiskach sieciowych, dlatego warto inwestować w naukę programowania. Ciągłe dokształcanie się i śledzenie nowości technologicznych to nie wybór, ale konieczność w tej dynamicznie rozwijającej się dziedzinie.
Na zakończenie kursu spójrzmy na pełny proces enkapsulacji danych – od aplikacji użytkownika aż do wysłania bitów na medium. To ilustruje, jak wszystkie warstwy współpracują ze sobą.
- Warstwa aplikacji (L7): Aplikacja generuje dane (np. HTTP GET /index.html). Dane trafiają do gniazda.
- Warstwa transportowa (L4): Dzieli dane na segmenty. Dodaje nagłówek TCP/UDP z portami źródłowym i docelowym oraz numerami sekwencyjnymi (TCP).
- Warstwa sieciowa (L3): Segmenty zostają opakowane w pakiety IP. Dodawany jest nagłówek IP z adresami źródłowym i docelowym (IPv4/IPv6) oraz polem TTL.
- Warstwa łącza danych (L2): Pakiety IP enkapsulowane są w ramki Ethernet. Dodawany jest nagłówek z adresami MAC (źródłowy, docelowy) i stopka z FCS (suma kontrolna).
- Warstwa fizyczna (L1): Ramka zamieniana jest na strumień bitów (sygnał elektryczny/świetlny) i transmitowana przez medium.
Proces enkapsulacji danych jest jednym z najważniejszych pojęć w sieciach komputerowych, ponieważ ilustruje, w jaki sposób dane aplikacji użytkownika są stopniowo opakowywane w kolejne nagłówki poszczególnych warstw. Na samej górze dane generowane przez aplikację, na przykład treść wiadomości e-mail lub żądanie strony internetowej, trafiają do warstwy transportowej, która dzieli je na mniejsze jednostki i dodaje nagłówek z numerami portów. Powstałe segmenty TCP lub datagramy UDP są następnie przekazywane do warstwy sieciowej, gdzie otrzymują nagłówek IP z adresami źródłowym i docelowym, polem TTL oraz znacznikami jakości usług. Na warstwie łącza danych całość zostaje opakowana w ramkę Ethernet, której nagłówek zawiera adresy MAC, a stopka pole FCS umożliwiające wykrycie błędów transmisji. Na samym dole warstwa fizyczna zamienia ramkę na strumień bitów wysyłany przez medium transmisyjne w postaci sygnału elektrycznego, świetlnego lub radiowego.
Po stronie odbiorcy zachodzi proces odwrotny, czyli dekapsulacja, w którym każda kolejna warstwa zdejmuje właściwy sobie nagłówek i przekazuje dane wyższej warstwie. Karta sieciowa odbiera bity z medium i składa je w ramkę, sprawdzając sumę kontrolną FCS i porównując docelowy adres MAC ze swoim adresem. Jeśli ramka jest przeznaczona dla danego urządzenia, jest dekapsulowana do pakietu IP, którego adres docelowy jest analizowany przez warstwę sieciową. Następnie segment TCP lub datagram UDP trafia do warstwy transportowej, która na podstawie numeru portu kieruje dane do odpowiedniej aplikacji. Ten elegancki mechanizm enkapsulacji i dekapsulacji pozwala na współdziałanie zupełnie różnych technologii i producentów w ramach jednej globalnej sieci, stanowiąc fundament działania całego Internetu.
Warte polecenia książki:
- Andrew S. Tanenbaum – „Sieci komputerowe" (wydanie V) – klasyczna pozycja, która powinna znaleźć się na półce każdego inżyniera sieci.
- Wendell Odom – „CCNA 200-301 Official Cert Guide" (vol. 1 & 2) – świetne źródło wiedzy praktycznej i teoretycznej, standard w przygotowaniu do certyfikacji Cisco.
- Richard Froom – „Cisco Switching Black Book" – szczegółowe omówienie przełączania, VLAN, STP.
- James Boney – „Cisco IOS Quick Reference" – przydatna ściągawka z poleceń IOS.
Dokumenty RFC
- RFC 791 – Internet Protocol (IPv4)
- RFC 793 – Transmission Control Protocol (TCP)
- RFC 826 – Ethernet Address Resolution Protocol (ARP)
- RFC 768 – User Datagram Protocol (UDP)
- RFC 8200 – Internet Protocol, Version 6 (IPv6)
Literatura przedmiotu jest niezwykle bogata, ale kilka pozycji wybija się jako absolutnie fundamentalne dla każdego uczącego się sieci komputerowych. Andrew Tanenbaum w swojej książce "Sieci komputerowe" przedstawia wyczerpujący przegląd wszystkich warstw modelu OSI, łącząc głębię teoretyczną z praktycznymi przykładami i historią rozwoju poszczególnych technologii. Podręczniki Wendella Odma do certyfikacji CCNA są cenione za przystępny język, liczne analogie i systematyczne podejście do nauki, które sprawdza się zarówno u początkujących, jak i u zaawansowanych inżynierów. Dokumenty RFC stanowią oficjalne specyfikacje protokołów internetowych i są ostatecznym źródłem prawdy w przypadku wątpliwości co do szczegółów implementacyjnych. Wiele z tych dokumentów, takich jak RFC 791 dla protokołu IPv4 czy RFC 793 dla TCP, pozostaje aktualnych od dziesięcioleci, co świadczy o solidności fundamentów Internetu.
Warto również sięgać do dokumentacji producentów sprzętu sieciowego, która często zawiera szczegółowe opisy mechanizmów działania wraz z konkretnymi przykładami konfiguracji. Oficjalne przewodniki konfiguracyjne Cisco, Juniper i Fortinet są dostępne bezpłatnie w Internecie i stanowią doskonałe źródło wiedzy praktycznej. Czasopisma branżowe i blogi techniczne pozwalają śledzić najnowsze trendy i zagrożenia, które nie zawsze znajdują odzwierciedlenie w podręcznikach akademickich. Fora dyskusyjne i społeczności takie jak Reddit czy grupy specjalistyczne na LinkedIn umożliwiają wymianę doświadczeń z innymi praktykami i uzyskanie pomocy w rozwiązywaniu konkretnych problemów. Łączenie wiedzy z podręczników z praktyką laboratoryjną i wymianą doświadczeń w społeczności to sprawdzona droga do stania się kompetentnym inżynierem sieci.
Gdzie szukać wiedzy za darmo:
- Packet Tracer (Cisco): Darmowy symulator sieci do nauki konfiguracji IOS. Idealny dla początkujących do ćwiczenia VLAN, STP, routingu, ACL.
- GNS3 / EVE-NG: Zaawansowane emulatory sieci umożliwiające uruchamianie rzeczywistych obrazów IOS, NX-OS, JunOS i innych.
- Wireshark: Niezastąpione narzędzie do analizy ruchu sieciowego (sniffing, analiza protokołów, troubleshooting).
- Kursy online: YouTube (David Bombal, Keith Barker, Jeremy's IT Lab), Cisco NetAcad, Udemy.
- Społeczności: Reddit r/ccna, r/networking, NetworkLessons.com, PacketLife.net.
Symulator Packet Tracer od firmy Cisco jest dostępny bezpłatnie dla uczniów i nauczycieli i stanowi doskonałe narzędzie do nauki konfiguracji przełączników i routerów bez konieczności posiadania fizycznego sprzętu. Zaawansowani użytkownicy powinni sięgnąć po emulatory GNS3 i EVE-NG, które umożliwiają uruchamianie rzeczywistych systemów operacyjnych urządzeń sieciowych na maszynach wirtualnych, oferując środowisko niemal identyczne z produkcyjnym. Wireshark to narzędzie obowiązkowe dla każdego inżyniera sieci, pozwalające przechwytywać i analizować ruch sieciowy w czasie rzeczywistym, co jest nieocenione przy nauce protokołów i diagnozowaniu problemów. Kanały YouTube takie jak David Bombal, Keith Barker czy Jeremy’s IT Lab oferują setki godzin bezpłatnych tutoriali obejmujących zarówno podstawy, jak i zaawansowane tematy sieciowe. Platformy szkoleniowe typu Udemy i Coursera udostępniają kursy w przystępnych cenach, często z praktycznymi laboratoriami i ćwiczeniami.
społeczność sieciowa na Reddicie, a szczególnie grupa r/ccna i r/networking, to miejsca, gdzie początkujący mogą zadawać pytania i uzyskać pomoc od doświadczonych specjalistów z całego świata. Strony takie jak NetworkLessons.com i PacketLife.net oferują starannie przygotowane artykuły i diagramy wyjaśniające skomplikowane zagadnienia w przystępny sposób. Dokumentacja techniczna producentów, taka jak Cisco Learning Network, zawiera nie tylko opisy protokołów, ale także gotowe scenariusze laboratoryjne i studia przypadków. Laboratoria chmurowe, na przykład Cisco DevNet Sandbox, umożliwiają eksperymentowanie na rzeczywistych urządzeniach bez konieczności posiadania własnej infrastruktury. Kluczem do sukcesu jest systematyczność i regularne ćwiczenie, ponieważ sieci komputerowe to dziedzina, w której teoria bez praktyki pozostaje tylko suchą wiedzą książkową.
Koniec cyklu wykładów
Dziękuję Państwu za wytrwałość i zaangażowanie w trakcie całego kursu „Budowa i konfiguracja urządzeń sieciowych". Mamy nadzieję, że zdobyta wiedza stanowi solidny fundament do dalszego rozwoju w obszarze sieci komputerowych i bezpieczeństwa IT. Zachęcamy do kontynuowania nauki, zdobywania certyfikatów (CCNA, Network+, JNCIA) oraz praktycznego eksperymentowania w laboratoriach sieciowych. Sieci komputerowe to fascynująca dziedzina, która nieustannie ewoluuje – warto być jej częścią!
Powodzenia na egzaminach i w przyszłej karierze zawodowej!
Serdecznie dziękujemy wszystkim słuchaczom za wytrwałość i zaangażowanie w trakcie całego cyklu wykładów poświęconych budowie i konfiguracji urządzeń sieciowych. Mamy nadzieję, że zdobyta wiedza stanowi solidny fundament, na którym możecie Państwo budować dalsze kompetencje w fascynującym świecie sieci komputerowych. Zachęcamy do kontynuowania nauki poprzez zdobywanie uznanych certyfikatów branżowych, takich jak Cisco CCNA, CompTIA Network+ czy Juniper JNCIA. Certyfikacje te nie tylko potwierdzają wiedzę, ale także otwierają drzwi do atrakcyjnych ofert pracy i stanowią międzynarodowy standard oceny umiejętności sieciowych. Pamiętajcie Państwo, że najcenniejsze lekcje płyną z praktyki własnych rąk przy konfiguracji i rozwiązywaniu problemów w rzeczywistych środowiskach laboratoryjnych.
Świat sieci komputerowych nieustannie ewoluuje, dlatego warto śledzić nowe technologie i rozwijać się równolegle w obszarach takich jak automatyzacja, bezpieczeństwo i przetwarzanie w chmurze. Umiejętność łączenia wiedzy o tradycyjnych protokołach z nowoczesnymi narzędziami programistycznymi będzie w najbliższych latach szczególnie ceniona na rynku pracy. Życzymy Państwu sukcesów na egzaminach, w dalszej edukacji oraz w karierze zawodowej, mając nadzieję, że nasz kurs był pierwszym krokiem w długiej i satysfakcjonującej podróży. Niech Wasze pakiety zawsze trafiają do celu, a routing niech będzie najkrótszą możliwą ścieżką do sukcesu. Powodzenia!
Jednostki PDU (Protocol Data Unit) dla każdej warstwy modelu OSI – szybka ściągawka na egzamin:
- Warstwa aplikacji (L7), prezentacji (L6), sesji (L5): Dane (Data) – ogólna nazwa dla informacji przesyłanych między aplikacjami.
- Warstwa transportowa (L4): Segment (TCP) lub Datagram (UDP) – nagłówek z portami + dane.
- Warstwa sieciowa (L3): Pakiet (Packet) – nagłówek IP (adresy źródłowy/docelowy IP, TTL) + dane.
- Warstwa łącza danych (L2): Ramka (Frame) – nagłówek (adresy MAC źródłowy/docelowy, EtherType) + dane + FCS (trailer).
- Warstwa fizyczna (L1): Bity (Bits) – surowy strumień bitów na medium.
Jednostki danych protokołu PDU różnią się w zależności od warstwy, na której występują, i ich poprawne rozróżnianie jest niezbędne na egzaminach oraz w codziennej pracy inżyniera sieci. Na trzech najwyższych warstwach, czyli aplikacji, prezentacji i sesji, jednostki te określa się wspólnym mianem danych, ponieważ protokoły tych warstw operują na informacjach bezpośrednio związanych z działaniem aplikacji. Warstwa transportowa wprowadza rozróżnienie między segmentem dla protokołu TCP, który jest niezawodny i połączeniowy, a datagramem dla protokołu UDP, który jest lekki i bezpołączeniowy. Na warstwie sieciowej jednostka PDU nosi nazwę pakietu i zawiera nagłówek IP z adresami logicznymi, które umożliwiają dostarczenie danych przez wiele sieci pośrednich. Warstwa łącza danych operuje na ramkach, które opakowują pakiety w nagłówki z adresami MAC i stopkę z sumą kontrolną FCS.
Zapamiętanie tej terminologii ułatwia zrozumienie procesu enkapsulacji, w którym każda warstwa dodaje własny nagłówek do otrzymanej jednostki z warstwy wyższej. Kiedy aplikacja wysyła dane, są one kolejno opakowywane w segment lub datagram, następnie w pakiet, później w ramkę, aż w końcu zamieniają się w strumień bitów na medium transmisyjnym. Po stronie odbiorczej każda warstwa odczytuje i usuwa nagłówek swojej warstwy, po czym przekazuje zawartość warstwie wyższej do dalszego przetworzenia. Warto zauważyć, że w praktyce wiele osób używa tych terminów zamiennie, ale podczas egzaminów certyfikacyjnych precyzja terminologiczna ma kluczowe znaczenie. Znajomość jednostek PDU jest szczególnie pomocna przy analizie zrzutów z Wiresharka, gdzie każde przechwycone ramce przyporządkowana jest odpowiednia warstwa i typ jednostki.
Mapowanie urządzeń sieciowych na warstwy OSI wraz z typami adresów, którymi operują na poszczególnych warstwach – przydatne zestawienie do powtórki.
- Warstwa 1 (Fizyczna): Hub, Repeater, Media Konwerter – nie analizują adresów, operują na sygnałach elektrycznych/optycznych.
- Warstwa 2 (Łącza danych): Most (Bridge), Przełącznik (Switch L2) – operują na adresach MAC (48-bit, np. AA:BB:CC:DD:EE:FF).
- Warstwa 3 (Sieciowa): Router, Przełącznik L3 (Multilayer Switch) – operują na adresach IP (IPv4 – 32-bit, np. 192.168.1.1; IPv6 – 128-bit).
- Warstwa 4 (Transportowa): Firewall (stateful), Load Balancer L4 – operują na portach TCP/UDP (16-bit, 0-65535).
- Warstwa 7 (Aplikacji): Proxy, WAF, Load Balancer L7 – operują na treści aplikacji (URL, nagłówki HTTP, cookies, payload).
Każde urządzenie sieciowe operuje na określonej warstwie lub warstwach modelu OSI, a typ adresu, którym się posługuje, wynika bezpośrednio z jego miejsca w hierarchii modelu referencyjnego. Na warstwie fizycznej urządzenia takie jak koncentratory i wzmacniacze nie analizują żadnych adresów, a jedynie regenerują i wzmacniają sygnał elektryczny lub optyczny, działając wyłącznie na poziomie bitów. Przełączniki warstwy drugiej podejmują decyzje na podstawie adresów MAC, które są 48-bitowymi identyfikatorami nadawanymi fabrycznie każdemu interfejsowi sieciowemu. Routery i przełączniki wielowarstwowe operują na adresach IP warstwy trzeciej, które są adresami logicznymi przypisywanymi przez administratora i mogą zmieniać się w zależności od sieci, w której znajduje się urządzenie. Firewalle stanowe i load balancery warstwy czwartej analizują dodatkowo porty TCP i UDP, co pozwala im rozróżniać poszczególne typy ruchu i aplikacji.
Urządzenia warstwy siódmej, takie jak serwery proxy i zapory aplikacyjne, sięgają najgłębiej, analizując nie tylko nagłówki, ale także zawartość przesyłanych danych, w tym adresy URL, nagłówki HTTP i treść żądań. Zrozumienie tego mapowania jest kluczowe przy projektowaniu polityk bezpieczeństwa, ponieważ reguła firewalla może działać na różnych poziomach szczegółowości w zależności od możliwości urządzenia. W praktyce inżynierskiej często spotyka się urządzenia wielowarstwowe, które łączą funkcje kilku warstw w jednym sprzęcie, co wymaga od administratora świadomości, na którym poziomie odbywa się filtrowanie czy przekazywanie ruchu. Na przykład przełącznik L3 routuje między sieciami VLAN sprzętowo, ale jednocześnie może oferować podstawowe listy ACL warstwy trzeciej i czwartej. Im wyższa warstwa, tym większe możliwości analizy i kontroli, ale także większe zapotrzebowanie na moc obliczeniową i potencjalne opóźnienia w przetwarzaniu pakietów.
Praktyczne zasady bezpiecznej konfiguracji urządzeń sieciowych – checklista dla inżyniera:
- Zawsze zmieniaj domyślne hasła i nazwy użytkowników (disable default accounts, enable secret z silnym hasłem).
- Wyłącz nieużywane usługi i porty (np. HTTP serwer na switchu, Telnet, CDP/LLDP na granicy sieci).
- Stosuj zasadę najmniejszych uprawnień (least privilege) w ACL – blokuj wszystko domyślnie, otwieraj tylko to, co niezbędne.
- Segmentuj sieć za pomocą VLAN i firewall rules – izoluj ruch produkcyjny, zarządczy i gościnny (guest network).
- Regularnie aktualizuj oprogramowanie (IOS, firmware) i śledź biuletyny bezpieczeństwa producenta.
- Włącz logowanie i monitoring (syslog, SNMP, NetFlow/IPFIX) – bez logów nie ma wykrywalności incydentów.
- Stosuj szyfrowanie zarządzania (SSH zamiast Telnet, HTTPS zamiast HTTP, SNMPv3 zamiast v2c).
Bezpieczna konfiguracja urządzeń sieciowych zaczyna się od zmiany domyślnych haseł i nazw użytkowników, ponieważ są one powszechnie znane i stanowią pierwszy cel ataków automatycznych skanerów. Należy bezwzględnie wyłączyć wszystkie nieużywane usługi i protokoły, takie jak serwer HTTP na przełączniku, Telnet przesyłający dane w postaci jawnej oraz protokoły CDP i LLDP na interfejsach granicznych sieci. Zasada najmniejszych uprawnień w listach ACL oznacza, że domyślnie cały ruch powinien być blokowany, a administrator świadomie otwiera tylko te porty i protokoły, które są niezbędne do działania aplikacji. Segmentacja sieci za pomocą VLAN i odpowiednich reguł firewalla zapobiega rozprzestrzenianiu się zagrożeń między różnymi strefami, na przykład między siecią produkcyjną, zarządczą i gościenną. Regularne aktualizacje oprogramowania sprzętowego i śledzenie biuletynów bezpieczeństwa producentów pozwalają łatać podatności, zanim zostaną wykorzystane przez napastników.
Logowanie i monitoring to fundament wykrywalności incydentów bezpieczeństwa, ponieważ bez szczegółowych dzienników zdarzeń niemożliwe jest ustalenie przyczyny i zakresu włamania. Systemy syslog umożliwiają centralne gromadzenie logów z wielu urządzeń, a protokół SNMP w wersji trzeciej z szyfrowaniem i uwierzytelnianiem zastępuje niebezpieczne wersje drugą i pierwszą. Połączenia zarządcze do urządzeń powinny być zawsze szyfrowane przy użyciu protokołu SSH zamiast jawno-tekstowego Telnetu, a interfejsy WWW powinny obsługiwać wyłącznie HTTPS. Dla zwiększenia bezpieczeństwa warto stosować scentralizowane systemy uwierzytelniania, takie jak RADIUS lub TACACS+, które umożliwiają zarządzanie kontami i hasłami z jednego punktu. Wreszcie, każda zmiana konfiguracji powinna być poprzedzona wykonaniem kopii zapasowej i udokumentowana zgodnie z procedurami zarządzania zmianami.
Serdecznie gratulujemy ukończenia kursu „Budowa i konfiguracja urządzeń sieciowych"! Przeszedłeś długą drogę od podstaw fizycznej transmisji bitów, przez adresację MAC i IP, aż po zaawansowane urządzenia bezpieczeństwa i równoważenia obciążenia.
Masz teraz solidne zrozumienie tego, jak działają sieci komputerowe – od sygnału na kablu aż po aplikację w przeglądarce. Pamiętaj, że teoria to dopiero początek – prawdziwe umiejętności zdobędziesz poprzez praktykę w laboratorium (Packet Tracer, GNS3), konfigurację rzeczywistego sprzętu oraz rozwiązywanie realnych problemów sieciowych.
Życzymy Ci sukcesów w dalszej edukacji i karierze – niech routing zawsze będzie optymalny, a pakiety niech docierają bez strat!
Serdecznie gratulujemy ukończenia kursu Budowa i konfiguracja urządzeń sieciowych, który przeprowadził Was przez wszystkie warstwy modelu OSI, od fizycznego przesyłania bitów po zaawansowane urządzenia bezpieczeństwa. Przez cały cykl wykładów zdobyliście wiedzę o adresacji MAC i IP, przełącznikach i routerach, protokołach routingu oraz mechanizmach bezpieczeństwa takich jak firewalle, systemy IPS i koncentratory VPN. Każda część kursu budowała fundament pod kolejną, tworząc spójny obraz funkcjonowania nowoczesnych sieci komputerowych w skali od małej sieci domowej po globalny Internet. Pamiętajcie jednak, że teoria to dopiero połowa sukcesu, a prawdziwe mistrzostwo zdobywa się poprzez samodzielną konfigurację urządzeń i rozwiązywanie realnych problemów w laboratorium. Gorąco zachęcamy do eksperymentowania w symulatorach i emulatorach, ponieważ każda spędzona przy konsoli minuta utrwala wiedzę i buduje intuicję inżynierską.
Dalsza ścieżka rozwoju może prowadzić w kierunku specjalizacji w obszarze bezpieczeństwa sieciowego, automatyzacji, sieci chmurowych lub projektowania rozległych infrastruktur operatorskich. Warto rozważyć zdobycie certyfikatu CCNA jako pierwszego formalnego potwierdzenia kompetencji, który jest rozpoznawalny na całym świecie i stanowi bramę do bardziej zaawansowanych ścieżek certyfikacyjnych. Społeczność sieciowa jest niezwykle otwarta i pomocna, dlatego nie bójcie się zadawać pytań na forach i grupach dyskusyjnych, ponieważ każdy ekspert kiedyś zaczynał od podstaw. Życzymy Wam, aby routing w Waszej karierze był zawsze optymalny, a pakiety docierały bez strat i opóźnień. Do zobaczenia w kolejnych kursach i powodzenia w dalszej edukacji sieciowej!